Big data
Capítulo 6. Big data y ciberseguridad
Página 12 de 16
CAPÍTULO 6
Big data y ciberseguridad
Introducción
Como hemos indicado, un rasgo definitorio de nuestra sociedad, y también en gran medida origen del fenómeno big data que nos interesa en este libro, es su casi ubicua digitalización. Esta se refleja en los sistemas de información, que almacenan datos confidenciales sumamente valiosos; en las redes sociales, que reflejan una parte importante de nuestra actividad personal privada; en los sistemas ciberfísicos, que controlan industrias, vehículos o infraestructuras críticas, o en los servicios electrónicos de compra, de banca o de administración, por mencionar unos pocos ejemplos.
En este estado de cosas, todo tipo de organizaciones, desde las grandes corporaciones a los gobiernos, pasando por las pymes conectadas y las familias, pueden quedar fuertemente impactadas por ciberataques. De hecho, los efectos económicos de estas amenazas son considerables y, en consecuencia, la ciberseguridad se ha convertido en una cuestión de importancia máxima, tanto técnica como financieramente: se percibe de manera creciente como una amenaza global como, por ejemplo, se destaca en la Estrategia de Seguridad Nacional 2019.
Realizaremos pues, en este capítulo, una reflexión sobre la relevancia del big data para ayudar a resolver uno de los mayores problemas sociales al que nos enfrentamos en la actualidad: el referido a la ciberseguridad. Tras contextualizar la cuestión desde una perspectiva económica, haremos una breve revisión crítica de los marcos actuales para promover la ciberseguridad. Después presentamos tres casos reales de aplicaciones de big data en ese campo.
Ciberseguridad: algo de contexto
Numerosas fuentes de información explican cómo los ciberataques están aumentando en frecuencia, impacto y sofisticación. Por ejemplo, se estima que tal tipo de ataques produjeron globalmente unos costes de cerca de 450 billones de dólares en 2016, causando un impacto sobre el PIB global (0,8% en 2014) similar en magnitud al del tráfico de drogas (0,9%) o al del crimen internacional tradicional (1,2%) (McAfee, 2017). Existen incluso mercados negros florecientes en la dark web en los que se intercambian herramientas de ataque o información robada, lo que crea incentivos para que personas y organizaciones suficientemente capacitadas y habilidosas desarrollen nuevos productos y servicios para perpetrar ciberataques. Aunque algunos expertos critican que, en cierta forma, se esté dando un bombo excesivo al potencial disruptivo de un ciberataque a escala global, la ciberseguridad es un problema muy relevante debido a la cada vez mayor persistencia, frecuencia y variedad de las ciberamenazas.
Tal diversidad puede clasificarse de acuerdo con la motivación, la capacidad y las restricciones de los potenciales atacantes, así como por su potencial para explotar, descubrir o crear vulnerabilidades en los sistemas objetivos de los ataques. Las amenazas más temibles provienen de las unidades cibermilitares de las potencias globales, aunque estas vienen ciertamente restringidas por sus posibles repercusiones militares, económicas y políticas en el contexto internacional. Otro origen de amenazas, ligado en ocasiones a movimientos sociales, es el de los hacktivistas, un perfil muy amplio que incluye a hackers que tratan de demostrar sus habilidades con actividades que bordean en ocasiones el terrorismo. Los atacantes internos constituyen otra importante fuente de amenazas —de hecho, la mayor—, pero, en principio, también son los más fáciles de gestionar a través de un buen programa interno de ciberseguridad adaptado a los estándares. Además, hay grupos cibercriminales centrados en obtener beneficios económicos con docenas de hackers como empleados y potentes recursos económicos para realizar ataques, tanto dirigidos como no dirigidos.
Un tipo muy relevante de ataque se realiza con ayuda de malware, término con el que normalmente designamos al software desarrollado con el objetivo de atacar a un sistema de información. El concepto de “amenaza persistente avanzada” ha surgido recientemente para designar ataques muy sofisticados consistentes en operaciones pacientemente orquestadas que buscan permanecer escondidas hasta que consolidan un camino para alcanzar su objetivo final. Algunos casos importantes incluyen la Operación Aurora, dirigida en 2007 contra Google para obtener datos confidenciales sobre sus algoritmos y sobre disidentes chinos, o Shamoon, que destruyó cerca de 30.000 ordenadores de Aramco en el año 2012. También hay ataques con importantes consecuencias físicas como el Stuxnet de 2010, que ralentizó la industria nuclear iraní durante un tiempo, o el ataque contra la industria siderúrgica alemana en 2014 que, como consecuencia, tuvo que parar sus operaciones de forma generalizada. Otra tendencia notable en los últimos años han sido los ataques indiscriminados basados en ransomware, como Wannacry y NotPetya en 2017, que afectaron a miles de organizaciones, grandes y pequeñas, durante varias horas.
Además, este será un problema cada vez más importante, pues numerosos elementos como los coches, los aviones, los sistemas médicos, los sistemas de inversión, abundantes infraestructuras críticas o los sistemas de votación van estando cada vez más influidos por las TIC, habiendo cada vez más sistemas interconectados a través del internet de las cosas.
Exploramos aquí como las metodologías y tecnologías de big data pueden ayudar en la resolución de estos problemas. Previamente describimos algunas metodologías estándar de ciberseguridad.
Metodologías para la ciberseguridad
El análisis de riesgos es una disciplina fundamental para la ciberseguridad. Con ella, las organizaciones pueden evaluar los riesgos que afectan a sus activos y qué contramedidas adoptar para reducir la probabilidad de que se materialicen y así mitigar su impacto en caso de que se produzcan. Existen numerosos marcos para discriminar los riesgos de ciberseguridad y apoyar la asignación de sus recursos, incluyendo los recogidos en ISO 27005, NIST SP 800-30, CORAS, CRAMM, EBIOS, ISAMM, Magerit, MEHARI o ISO 31000, entre algunos otros. Análogamente, hay diversos marcos de control de cumplimiento como ISO 27001, Common Criteria, ISO 27002, SANS Critical Security Controls, las leyes de protección de datos como la reciente RGPD, ISO 27031 o Cloud Security Alliance Cloud Control Matrix que, esencialmente, proporcionan guías sobre la implantación de mejores prácticas en ciberseguridad, incluyendo descripciones de las medidas de seguridad a adoptar para proteger los activos de una organización frente a las ciberamenazas a las que están expuestos.
Resulta interesante hacer una breve descripción del marco disponible más extenso, el NIST SP 800-30. Abarca procesos referidos a las distintas funciones de la ciberseguridad que comprenden la identificación de amenazas (principalmente desde una perspectiva táctico-estratégica de evaluación y gestión de riesgos), la protección frente a ellas (principalmente a través de actividades preventivas que incluyen, entre otras, el control de accesos y el uso de tecnologías de protección), su detección (por medio, entre otros, de la monitorización continua de la seguridad y de procesos de detección de sucesos y anomalías) y la respuesta y recuperación frente a las mismas (incluyendo su planificación y los correspondientes procesos de comunicación).
Aunque tienen sus virtudes —en especial los excelentes y muy detallados catálogos de amenazas, activos y contramedidas que incluyen y facilitan las tareas iniciales de ingeniería de seguridad— falta mucho por realizar en relación con el análisis de riesgos en este campo: un estudio detallado de las principales metodologías arriba mencionadas muestra cómo a menudo se basan en matrices de riesgos para la gestión, lo que presenta inconvenientes bien documentados, por ejemplo en Cox (2008), como serían las asignaciones ambiguas de probabilidades, impactos y riesgos y la promoción de evaluaciones erróneas y poco coherentes que pueden conducir, finalmente, a asignaciones de recursos inadecuadas. Más aún, con contadas excepciones como la de la metodología IS1 del gobierno británico, tales metodologías no tienen en cuenta explícitamente la intencionalidad de algunas de las ciberamenazas, una cuestión clave a la hora de predecir cuáles de ellas pueden dirigirse contra un sistema. Dada la variedad de amenazas, así como la complejidad específica de los factores que afectan a los sistemas críticos, creemos que, desde el punto de vista de la modelización, no se emplean métodos ni procesos de gestión de riesgos suficientemente detallados ni sofisticados en muchos casos.
En lo que sigue ilustraremos algunos ejemplos de aproximaciones algo más sofisticadas apoyadas en big data.
Big data para ciberseguridad
Monitorización masiva de redes
Comenzamos considerando el problema de la monitorización de redes. Dentro del protocolo NIST antes aludido nos encontraríamos en el proceso de detección y, dentro del mismo, en las fases de monitorización continua y detección de anomalías. Con las actividades que describimos tratamos de determinar y predecir si se producen cambios relevantes en el comportamiento de los elementos de una red o si se van a alcanzar niveles críticos para algunas de las variables de estado de dichos elementos.
Dada la importancia de tales actividades, se han desarrollado distintos sistemas de monitorización que, periódicamente y con alta frecuencia, recogen información sobre los sistemas interconectados de una organización para facilitar su monitorización. Por la creciente relevancia de las TIC, podemos enfrentarnos a organizaciones con varios centenares de miles de dispositivos interconectados de los que obtenemos decenas de variables cada pocos minutos. Tenemos, pues un ejemplo de problema en el que se capturan volúmenes muy altos de datos a muy alta velocidad. Además, hay cierta variedad en los datos a tratar pues, por ejemplo, algunas de las medidas que se recogen son continuas, como puede ser el porcentaje de uso de un disco, y otras son discretas, como el número de peticiones activas concurrentes a un sistema de base de datos. Esto plantea tremendos retos al procesamiento de datos para hacer las predicciones requeridas y apoyar la toma de decisiones en tiempo real para paliar problemas de seguridad en la red con suficiente antelación. Entre otras cosas, resulta virtualmente imposible que equipos de analistas humanos traten las series individualmente. Se crea así la necesidad de desarrollar un marco automatizado para realizar su análisis y un sistema que implemente tal marco. Además, muchos de los métodos estándar de análisis de series temporales no resultan útiles en nuestro contexto de monitorización masiva en tiempo real, bien porque no permiten tratar una cantidad tan enorme de datos de alta frecuencia, bien porque no pueden automatizarse debido a la versatilidad de las series a las que debemos enfrentarnos.
Necesitamos, pues, un marco con los siguientes requisitos funcionales, además del estándar en ciencia de datos que requiere que la metodología sea precisa (en el sentido de que debe alcanzar buen comportamiento predictivo):
Automático. Dada la gran cantidad de series temporales a monitorizar, la intervención de personas debería reducirse al mínimo.
Escalable. El marco debería ser escalable en tiempo y memoria. Ha de ser suficientemente rápido como para poder tratar series temporales de muy alta frecuencia. Además, debido a la enorme cantidad de series temporales a monitorizar, debería resumir y representarlas en unos pocos parámetros, evitando así almacenar toda(s) la(s) serie(s).
Versátil. Debe permitir, tanto en el caso discreto como el continuo, tratar series con características diferentes como son la posible presencia de fases de crecimiento lineal, elementos de estacionalidad o estallidos en la actividad asociada a las series, siempre de forma automática. Además, los rasgos de las series temporales pueden cambiar en el tiempo, por lo que el marco debe ser capaz de adaptarse dinámica y rápidamente a tales variaciones.
El interés del problema viene demostrado por el hecho de que dos grandes como Facebook y Twitter disponen de sistemas relacionados como son, respectivamente, Prophet y Anomaly Detection. Sin embargo, tales y otros sistemas no se adaptan específicamente a las necesidades del problema de monitorización de la seguridad en redes al que nos referimos. Por ello, en Naveiro et al. (2019) se propone un marco con alta capacidad predictiva completamente automatizable basado en una aproximación bayesiana que distingue entre series discretas y continuas. Para las series continuas se emplea una versión modificada de un tipo especial de modelos dinámicos lineales que incorpora información relativa a la presencia de estallidos regulares originados por procesos físicos tales como backups o compresiones, especialmente relevantes en este dominio de monitorización. Una ventaja importante de los modelos empleados es que pueden construirse empleando distintos bloques que capturan los rasgos específicos (tendencias, estacionalidad) de las series temporales. Debe introducirse también un método automático para identificar los modelos correspondientes. Además, estos modelos resumen los aspectos relevantes de la serie en unos pocos parámetros, posibilitando su escalabilidad espacial. Finalmente, el cálculo de las distribuciones predictivas es relativamente rápido haciendo la aproximación escalable en el tiempo. Para el segundo tipo de series se emplean cadenas de Markov en tiempo discreto.
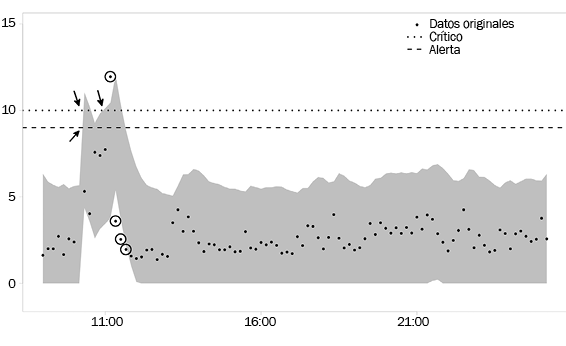
Describimos brevemente el uso del sistema correspondiente. Asociados a cada una de las series hay dos valores de referencia que designamos alerta (W) y crítico (C) referidos a niveles de observación tales que, en caso de ser excedidos, deberían conducir a emitir señales de aviso y de nivel crítico, respectivamente. Por ejemplo, para un disco de almacenamiento podríamos monitorizar su uso y hacer W = 0,9 y C = 0,95, significando que si alcanzamos un nivel de saturación del 95% del disco, su comportamiento podría degradarse e incluso colapsarse, produciendo una pérdida de servicio con los consiguientes costes económicos. Los umbrales dependerán del tipo de dispositivo y de su relevancia global. Obsérvese que empleamos un sistema de alarmas en dos niveles para tratar de obtener información más rica sobre fallos potenciales del dispositivo monitorizado. En el ejemplo indicado, W = 0,9 nos permite incrementar la atención antes de que sea demasiado tarde por alcanzarse el nivel crítico. Realizamos entonces dos tipos de predicciones:
A corto plazo. Nos permiten, por un lado, identificar el comportamiento anómalo de una serie cuando los valores observados no quedan dentro de los intervalos predictivos; esto se relaciona con cuestiones de seguridad y es útil para mostrar comportamientos críticos lo antes posible o detectar intrusos en el sistema. Por otro, nos permite lanzar alarmas cuando los intervalos predictivos cubren los umbrales W y/o C.
A largo plazo. Nos permite predecir estados críticos con tiempo suficiente cuando los umbrales W y/o C aparecen en los correspondientes intervalos predictivos.
La figura 6 representa una posible traza del sistema en la que se marcan el nivel de alerta y el nivel crítico. En ella se han marcado los instantes en los que los niveles críticos caen en los intervalos predictivos, así como los instantes en los que las observaciones quedan fuera de tales intervalos.
Figura 6
Traza de un sistema monitorizado.
Gestión de ciberriesgos en la cadena de suministro
Los terremotos, las crisis económicas, las huelgas, los ataques terroristas y otros sucesos pueden producir interrupciones significativas en las operaciones de una cadena de suministro, afectando de forma significativa a los resultados de una organización. Como ejemplo, Ericsson perdió 400 millones de euros tras el incendio en una planta de su proveedor de semiconductores en el año 2000. Tales disrupciones pueden tener también efectos negativos a largo plazo. Para su tratamiento ha surgido la disciplina de la gestión de riesgos en la cadena de suministro (GRCS) que proporciona estrategias para reducir las probabilidades de que se produzcan tales disrupciones y, en caso de que tengan lugar, su impacto sea lo menor posible. Como en otras aplicaciones de gestión de riesgos, la GRCS incluye procesos de identificación, evaluación, control y monitorización de riesgos.
Debido a la proliferación de los ciberataques, una cuestión de interés reciente, potenciada por la creciente interconectividad de las organizaciones, se refiere a la inclusión de los ciberriesgos en la GRCS. Un ejemplo importante de su relevancia es el caso del ciberataque a Target a través de su proveedor de aire acondicionado, mediante el que se robaron cerca de 70 millones de tarjetas de crédito en el año 2013. Por ello, han surgido distintos productos comerciales para la gestión de ciberriesgos en la cadena de suministros como Bitsight o Security Scorecard, aunque sus fundamentos son dudosos. Dentro del protocolo NIST antes aludido nos encontraríamos, por un lado en el proceso de detección y monitorización continua y, por otro, en el proceso de identificación en relación con la parte de evaluación de riesgos.
Como ejemplo consideremos una compañía interconectada con sus proveedores. La compañía puede sufrir ataques directos; ataques indirectos a través de sus proveedores que se transfieran a la compañía; y, finalmente, ataques a los proveedores que no se transfieren pero tienen consecuencias sobre la compañía por la no disponibilidad de un servicio o de un producto. Por ejemplo, en caso de que uno de los proveedores de la compañía quedase infectado por algún tipo de malware, el atacante podría escanear la red de la compañía y enviar emails infectados a la misma, que quedaría más probablemente infectada, pues el software recibido se originaría desde una fuente legítima.
Para la gestión de estos ciberriesgos, la compañía puede recoger grandes cantidades de datos de internet, típicamente a través de los denomimados “sistemas de inteligencia de amenazas”, que esencialmente se encargan de obtener información heterogénea de ingentes fuentes sobre la compañía y los proveedores sobre:
Vectores de ataque, que aportan indicios sobre ataques potenciales como las IP de los dispositivos que estén infectados por botnets o la información de login robada a través de las mismas.
El entorno de seguridad de las empresas, como el número de menciones negativas en blogs hacktivistas.
La postura de seguridad, como la cadencia de parcheo de aplicaciones en ellas.
Este es un proceso típico de ETL (extracción, transformación y carga) pero, además, incluye métodos no triviales de preprocesamiento, por ejemplo a la hora de clasificarse como negativa una entrada en un blog. Obsérvese que este es un problema de clasificación, con la especificidad de que debemos tratar con texto para realizarla. A partir de los datos antes mencionados intentamos determinar:
La probabilidad de que los proveedores de la compañía sean atacados.
La probabilidad de que la compañía sea atacada, bien directamente, bien a través de los proveedores.
Los impactos que tales ataques podrían inducir sobre la compañía.
Dadas las reticencias de estas a proporcionar datos relativos a los que designaríamos ataques suficientemente dañinos, empleamos métodos de juicios de expertos estructurados para mitigar su falta. Las probabilidades se estiman y predicen mediante modelos de regresión logística; los impactos se predicen mediante modelos econométricos y de ingeniería. Todos ellos se van actualizando mediante la fórmula de Bayes a medida que se van recibiendo datos. En conjunto, en cada paso temporal (por ejemplo, diariamente) el sistema funcionaría como sigue:
Escaneamos la red para obtener datos en relación con los vectores de ataque, la postura y el entorno de seguridad de la compañía y sus proveedores; los procesamos y consolidamos.
Estimamos a partir de ellos las probabilidades de ataque y sus impactos.
Agregamos la información anterior para estimar los riesgos.
Lanzamos las alarmas, si es necesario, cuando estos riesgos son demasiado altos o han variado ostensiblemente.
Presentamos los resultados.
Hacemos las predicciones de riesgo para el siguiente periodo.
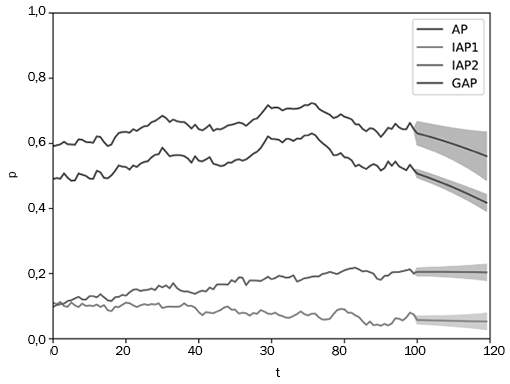
En la figura 7 se muestra la traza de cuatro índices de riesgos en los periodos de 0 a 100 (probabilidad de ataque a través de dos proveedores, de ataque directo y probabilidad total de ataque). A partir del periodo 100 se muestran las predicciones a través de los correspondientes intervalos predictivos. Se observa, por ejemplo, que el segundo proveedor induce más riesgo que el primero.
Figura 7
Trazas de índices de riesgo.
Clasificación adversaria
Como mencionamos en el capítulo 3, los problemas de clasificación son de los más relevantes en ciencia de datos dentro del aprendizaje supervisado. Tienen aplicaciones en numerosos campos como la detección de spam, la visión por ordenador o la genómica.
Sin embargo, hasta hace relativamente poco tiempo se ha ignorado una cuestión muy relevante en ciberseguridad: la presencia de adversarios que pueden manipular activamente los datos disponibles para engañar al clasificador con objeto de obtener cierto beneficio. Por ejemplo, alguien que envía spam intenta hacer creer al clasificador que el mensaje enviado es un correo legítimo, para poder obtener ventajas vendiendo la información obtenida de la víctima. Además, en tales contextos, al ir mejorando los algoritmos de clasificación, los adversarios van adaptando sus ataques al determinar los rasgos empleados por el clasificador para detectar spam. La presencia de adversarios adaptativos se ha mencionado también en áreas como la detección de fraude o en el desarrollo de sistemas de seguridad biométricos, entre otros, dando lugar a un campo muy activo en la actualidad que se denomina “de aprendizaje automático adversario”. Dentro del protocolo NIST antes aludido podríamos emplear estos métodos en la fase de protección para el control de accesos y el desarrollo de tecnologías de protección.
Dalvi et al. (2004) proporcionaron una aproximación pionera para mejorar un algoritmo de clasificación en presencia de adversarios, tomando como base un algoritmo Naive Bayes que tenga en cuenta las ganancias y pérdidas asociadas a acertar y errar en las clasificaciones. Para ello, presentan el problema de aprendizaje adversario como un juego entre un clasificador C y un adversario A. En primer lugar, C calcula su clasificador óptimo suponiendo que los datos no han sido modificados, como se describió en el capítulo 3; después, A, que se supone conoce tal clasificador, calcula su ataque óptimo frente al mismo; luego C implementa su clasificador óptimo frente a este ataque, y así sucesivamente. Sin embargo, como indican los propios autores, se hace una hipótesis muy fuerte: todos los parámetros de ambos jugadores son compartidos y conocidos por todos los participantes. Aunque esta condición, denominada “de conocimiento común”, es estándar en la denominada teoría de juegos (no cooperativa), no es, de hecho, realista en escenarios de ciberseguridad como los que consideramos, en los que los participantes tratan de esconder información. A pesar de ello, esta hipótesis ha permeado la mayoría de aproximaciones posteriores a este problema de clasificación adversaria.
Como alternativa surge la posibilidad de emplear métodos del análisis de riesgos adversarios. Para ello suponemos que estamos apoyando a C, que conoce los elementos de su problema, pero tiene incertidumbre sobre los elementos del problema de A (sus creencias y preferencias). Entonces podemos modelizar esta incertidumbre mediante distribuciones sobre tales creencias y preferencias y resolver el problema del atacante para encontrar los ataques más probables y, en función de ellos, encontrar el mejor clasificador frente a ataques, haciéndolos más efectivos y robustos.
Para saber más
En este capítulo hemos ilustrado cómo las tecnologías y metodologías big data pueden ayudar en el tratamiento de algunos problemas de ciberseguridad.
Un buen reflejo del problema aparece en los Global Risk Maps anuales que realiza el Foro Económico Mundial. El NIST, en su estándar SP 800-30, presenta un marco muy completo de gestión de la ciberseguridad, aunque adolece de promover métodos de gestión de riesgos basados en matrices de riesgos. .
Brutlag (2000) es una referencia clásica en el problema de detección de anomalías. El marco aquí descrito usa fuertemente los modelos dinámicos lineales y puede verse en Naveiro et al. (2018a).
Existen ya diversos sistemas comerciales para GCRCS como Bitsight o Security Scorecard, pero adolecen de fundamentos rigurosos. La aproximación aquí descrita está implementada en Blueliv y se presenta en más detalle en Redondo et al. (2018).
Una revisión reciente de la literatura sobre clasificación adversaria puede verse en Biggio et al. (2018). La mayoría de estos trabajos se basa en teoría de juegos no cooperativa, apoyada en el concepto de equilibrio de Nash y variantes, como se detalla en Menache y Ozdaglar (2011). Una aproximación alternativa al análisis de conflictos está en el análisis de riesgos adversarios que se describe en Banks et al. (2015). Naveiro et al. (2018b) proporcionan una aplicación a detección de spam.