Papers with Code - Papers with Code Newsletter #8
paperswithcode.comApril 16, 2021
Papers with Code Newsletter #8
Welcome to the 8th issue of the Papers with Code newsletter. In this edition, we cover:
- a list of the top 10 trending papers on Papers with Code for the month of March,
- recent progress in efficient training of large scale language models,
- a new efficient model for computer vision tasks,
- a transformer model trained to perform six software engineering tasks,
- ...and much more.
Trending Papers with Code 📄
🏆 Top Trending Papers of March 2021
A new addition to the newsletter is highlighting top papers of the month. Here is a list of the top 10 trending papers on Papers with Code for the month of March:
💬 Revisiting Neural Probabilistic Language Models
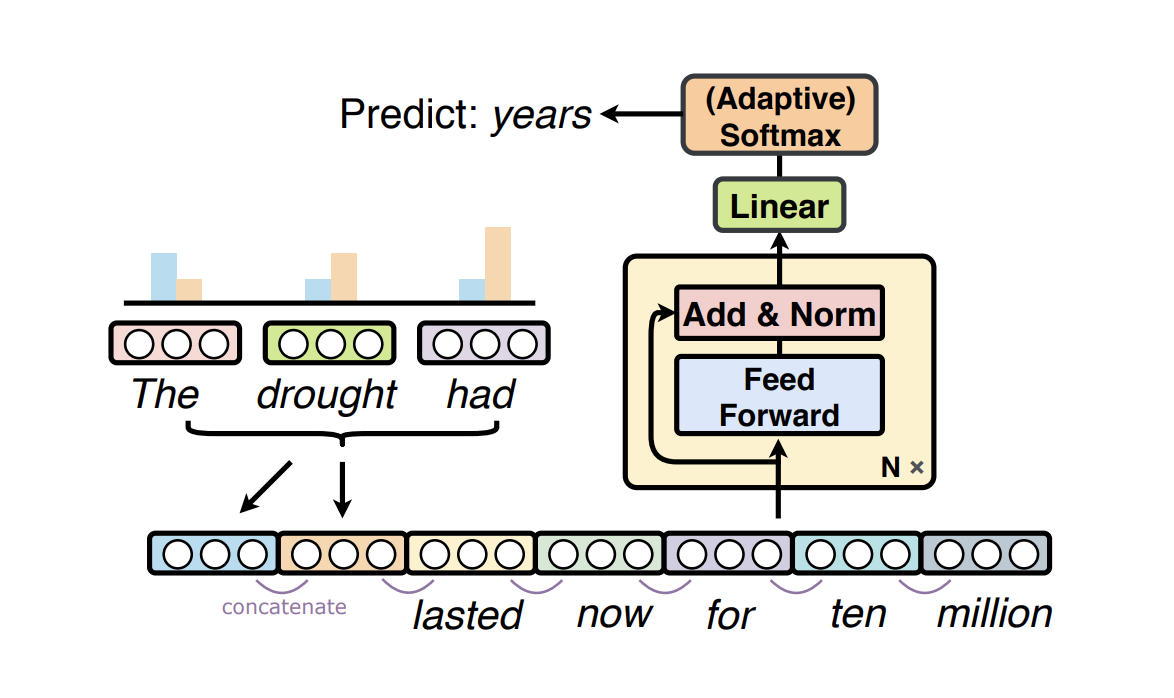
Modernized NPLM which concatenates representations of the distant context. Figure source: Sun and Iyyer (2021)
Recent developments and progress in language models are driven by advances in neural network architectures, availability of compute at scale (hardware), and large datasets. One of the earlier language models is the neural probabilistic language model (NPLM), proposed by Bengio et al. (2003), which uses a fixed window to concatenate word embeddings and passes results through a feed-forward neural network to predict the next word. Sun and Iyyer (2021) recently published a paper that revisits NPLMs by scaling this family of models to modern hardware. Besides studying NPLMs more closely, the authors also study the performance of these models when combined with the more recent transformer architecture.
What's new: This paper investigates more closely the limitations of NPLMs such as lack of parameter sharing and small context window and to what extent these could be mitigated using modern design and optimization. The proposed modernized NPLM incorporates changes such as increasing depth and window size, residual connections, layer normalization, and dropout. Through these modifications, the perplexity is substantially decreased (216 to 31.7) as compared to the original NPLM on WikiText-103. Results indicate that NPLM outperforms a Transformer model when given shorter prefixes. Elements of the NPLM are then incorporated to Transformer LMs which improves performance across three word-level LM datasets.
🗣 SpeechStew
More recently, there has been rapid progress in speech recognition: from incorporating new techniques, to scaling model capacity, to more innovative and feature-rich libraries. Some of the recent improvements in speech recognition are attributed to large deep models and abundance of training data. While some recent end-to-end speech recognition models have shown improvements they suffer from overfitting issues on low-resource datasets. Techniques like multi-lingual training and transfer learning have helped with generalization. To continue building on these ideas, Chan et al. (2021) recently proposed a simple approach to end-to-end speech recognition, which leverages both multi-domain and transfer learning.
Key ideas: SpeechStew trains a single large neural network on a combination of various publicly available speech recognition datasets such as Common Voice and LibriSpeech. The combination of datasets is done without any domain-dependent re-balancing and re-weighting. No domain labels or additional hyperparameters are used for combining the data. Without relying on external language models as prior work do, SpeechStew achieves state-of-the-art or near state-of-the-art results on various tasks. The transfer learning capabilities of the model allows simple fine-tuning on unseen data that results in strong empirical results. Overall, the results in this work encourages the possibility to leverage all available data as opposed to training on only task-specific datasets.
⚡️ Efficiently Training Large Language Models on GPU Clusters
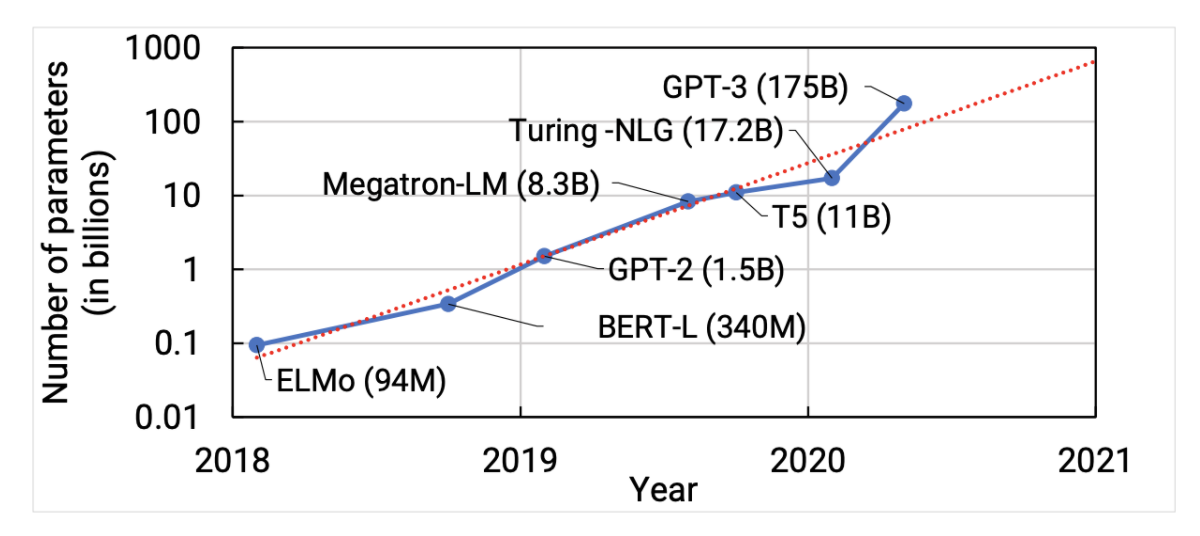
Trends of sizes state-of-the-art NLP models over time. Figure source: Narayanan et al. (2021)
The effectiveness of large language models on a variety of NLP tasks has been possible due to the availability of computation at scale and larger datasets. However, training large-scale language models requires efficient use of compute resources. Specifically, the large number of parameters present in these models makes it challenging as GPU memory capacity becomes insufficient and training times become longer. Narayanan et al. (2021) show ways to compose different parallelism methods such as data parallelism and pipeline model parallelism to more efficiently scale large language model training on GPU clusters.
What's new: This work proposes to combine different types of parallelism methods to efficiently scale large language model training to thousands of GPUs. They achieve two-order-of-magnitude increase in sizes of models that can efficiently be trained as compared to existing systems. The authors propose a novel schedule that can improve throughput by more than 10% with comparable memory footprint as compared to previously-proposed approaches. The combination of parallelism techniques allows training iterations on a model with 1 trillion parameters at 502 petaFLOP/s on 3072 GPUs with per-GPU throughput of 52% of peak, which is a higher throughput compared to previous efforts to train similar-sized models (36% of theoretical peak).
🔋 EfficientNetV2
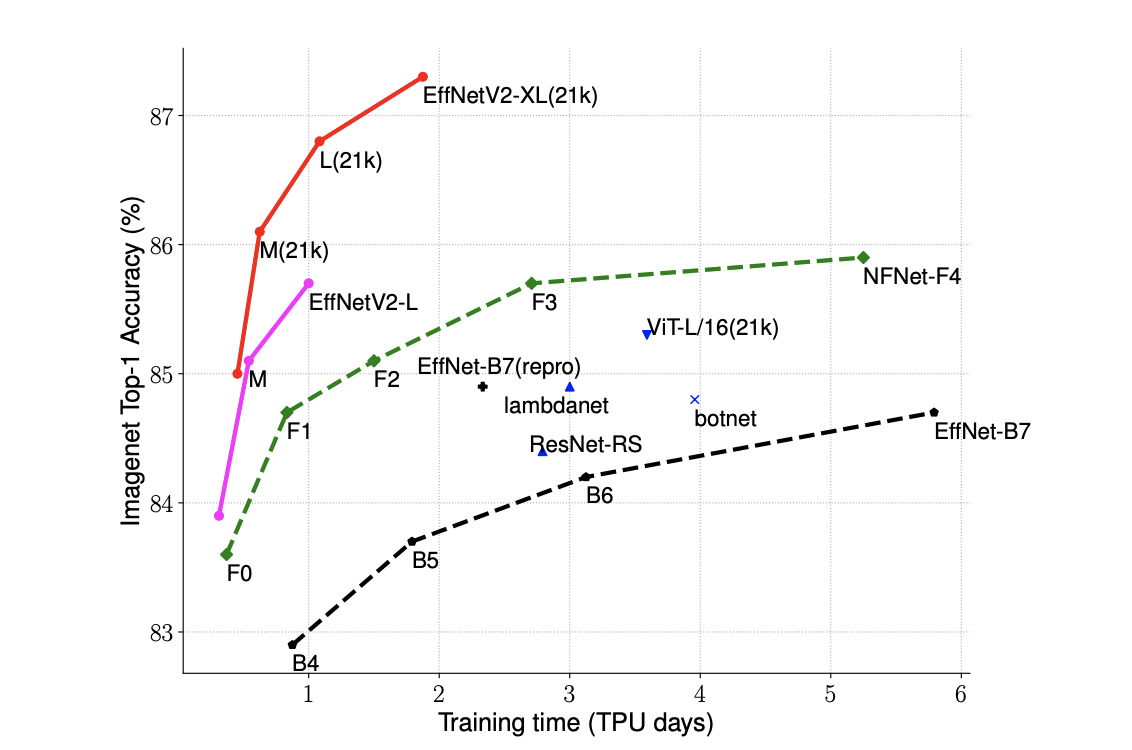
ImageNet ILSVRC2012 top-1 accuracy - Accuracy vs. Training time (i.e., Training efficiency). Figure source: Tan and Le (2021)
In a previous newsletter, we highlighted important recent works and progress on efficient ML models. One of the more popular methods is called EfficientNet, a convolutional neural network architecture which shows that carefully balancing network depth, width, and resolution can lead to better performance. More recently, Tan and Le (2021) proposed a newly improved EfficientNet model called EfficientNetV2 with faster training speed and better parameter efficiency than previous models.
What's new: EfficientNetV2 combines training-aware neural architecture search and scaling to jointly optimize training speed and parameter efficiency. It is trained with an improved method of progressive learning which adaptively adjusts regularization along with image size. This method speeds up training and keeps accuracy from dropping. EfficientNetV2 significantly outperforms previous models on ImageNet and CIFAR/Cars/Flowers datasets. By pretraining on ImageNet21K, EfficientNetV2 also outperforms the recently proposed ViT-L/16 model by 2.0% accuracy on ImageNet ILSVRC2012 while training 5x-11x faster.
⌨️ Code Transformer - On Understanding Source Code Language
The automatic understanding of source code language has recently sparked interest in the field of natural language processing (NLP). This line of research has the potential to be used for building applications that improve the software engineering process. Elnaggar et al. (2021) recently proposed to use self-supervised deep learning including an encoder-decoder transformer model for tasks in the software engineering domain.
Why it matters: Understanding source code language for improving on automated software engineering tasks has been under-researched. The authors combine the latest NLP techniques to extensively study their effectiveness on six software engineering tasks, including 13 subtasks. Many different training strategies such as single-task learning and multi-task learning were used to evaluate models. Pretrained models are also made available to further encourage ML research in the software engineering domain. See detailed results on the main tasks using the table below.

Results produced by the Transformer model on various software engineering tasks. Table source: Elnaggar et al. (2021)
Trending Libraries and Datasets 🛠
Trending datasets
DexYCB - a dataset for capturing hand-grasping of objects used for three tasks: 2D object and keypoint detection, 6D object pose estimation, and 3D hand pose estimation.
Casual Conversations - a dataset designed to help researchers evaluate computer vision and audio models across a diverse set of age, genders, apparent skin tones and ambient lighting conditions.
SpartQA - a new textual QA benchmark for spatial reasoning on natural language text.
Trending libraries
TextFlint - a new NLP toolkit and multilingual robustness platform that provides comprehensive robustness analysis.
LayoutParser - a new open-source library for streamlining the usage of deep learning in document image analysis research and applications.
Avalanche - an open-source end-to-end library, based on PyTorch, for continual learning research.
AutoGL - a library for automated graph learning.
Community Highlights ✍️
- Thanks to @jsssim for several contributions to leaderboards.
- Thanks to @hashreak for contributing to leaderboards including results for the recent work on Recursively Refined R-CNNs.
- Thanks to @Xinyu for contributing to methods including the submission of the AutoGAN method.
- Thanks to @Ijchangyu for several contributions, including the addition of the UAV-Human dataset for pose estimation and action recognition.
- Thanks to @myscarlet for contributions to Datasets including the addition of the LSARS dataset for multi-document summarization.
Special thanks to @xavigiro, @HTVR, @DegardinBruno, @Ijchangyu, @Johnaflalo, @Sanqing, @nicholashkust and the hundreds of contributors for all their contributions to Papers with Code.
More from Papers with Code 🗣
🎉 Introducing @paperswithdata
Introducing Papers with Datasets on Twitter. A curated, daily feed of newly published datasets in machine learning. Follow the Twitter handle (@paperswithdata) to stay updated with newest datasets.
👩💻 We are hiring!
We are hiring passionate engineers looking to make machine learning research more reproducible, discoverable, and extensible. Apply now to work with us on this mission: https://paperswithcode.com/careers
We would be happy to hear your thoughts and suggestions on the newsletter. Please reply to elvis@paperswithcode.com.
Source paperswithcode.com