Нейросеть научилась выделять голоса отдельных людей на видео
Stanislav Isakov
То, что наш мозг в шумной среде способен эффективно фокусироваться на конкретном собеседнике, “отключая” посторонние звуки - ни для кого не секрет. Этот феномен даже получил популярное название “эффект коктейльной вечеринки”. Но, несмотря на хорошую изученность явления, автоматическое выделение речи конкретного говорящего до сих пор остается сложной задачей для компьютеров.
В рамках проекта Looking to Listen была создана комбинированная аудио-визуальная модель, дающая возможность выделить из общего потока звуков (включая фоновый шум и голоса других людей) речь одного человека и заглушить все остальные звуки.
Метод работает на совершенно обычных видео с одной звуковой дорожкой. Все, что требуется от пользователи - выбрать лицо того человека на видео, которого они хотят слышать.
Поле применения у этой технологии широчайшее - от распознавания речи до усовершенствования слуховых аппаратов, которые сегодня плохо справляются со своей работой, если одновременно говорят несколько человек.
Новая технология использует сочетание аудио- и видеоряда для выделения речи. Благодаря движениям губ человека, точнее, их корреляции с произносимыми звуками, удается определить, какая именно часть аудиопотока связана с конкретным человеком. Это существенно повышает качество выделения речи (по сравнению с системами, обрабатывающими только аудиоряд), особенно в ситуации, когда говорящих - несколько.
Что более важно, технология позволяет распознать, кто именно из людей на видео и что именно говорит, связав уже выделенную речь с конкретными спикерами.
Как это работает?
В качестве тренировочных примеров для нейросети использовалась база из 100000 загруженных на YouTube видео лекций и бесед. Из них были выделены фрагменты с “чистой речью” (без фоновой музыки, звуков аудитории или речи других людей) и всего одним говорящим в кадре общей продолжительностью примерно 2000 часов.
Затем из “чистых” данных были созданы “синтетические коктейльные вечеринки” - видео, в которых были объединены лица спикеров, их предварительно выделенная речь и фоновые шумы, которые были взяты на AudioSet.
В результате удалось обучить сверточную нейросеть выделять из “коктейльной вечеринки” отдельный аудиопоток для каждого человека, говорящего на видео.
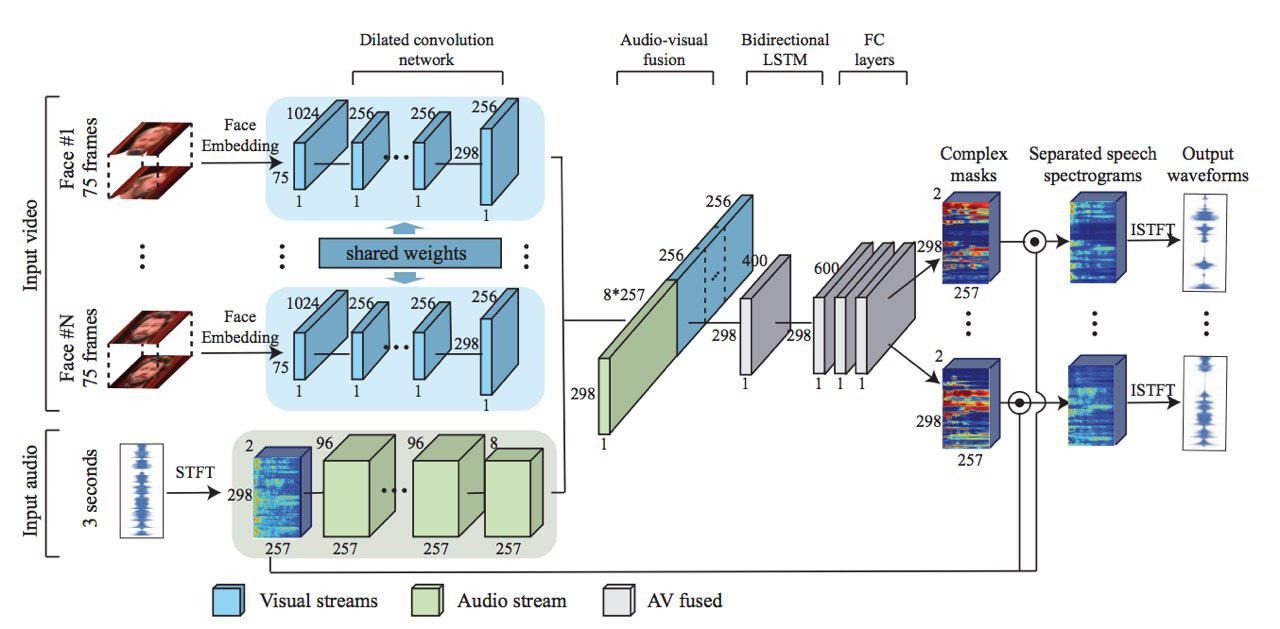
Сперва из видеопотока извлекаются распознанные лица, после чего сверточная нейросеть изучает черты каждого лица. Из аудиопотока, в свою очередь, сперва получаем спектрограмму используя STFT, а затем пропускаем ее через аналогичную нейросеть. Конечный результат получается путем соединения обработанных аудио- и видеосигналов, которые в дальнейшем обрабатываются с использованием двунаправленной LSTM и трех слоев глубокой сверточной нейросети.
Нейросеть создает сложную маску спектрограммы для каждого спикера, которая перемножается с “шумными” исходными данными и снова конвертируется в волновую форму, чтобы получить изолированный аудиосигнал для каждого спикера.
Подробнее о технологии и полученных результатах можно почитать в документации проекта и на его Github странице.
Результат
Ниже представлены результаты применения технологии. Все звуки, кроме речи выбранных людей, могут быть или отключены вовсе, или приглушены до необходимого уровня.
Данная технология может быть использована для распознавания речи и создания автоматических субтитров. Существующие системы не справляются в ситуациях, когда речь нескольких человек накладывается друг на друга. Разделение звука “по источникам” позволяет получить более точные и легко воспринимаемые субтитры.