Машинный перевод
@tany_savelievaВ чем суть?
Машинный перевод - достаточно старая и важная задача, в которой мы хотим получать на вход текст из одного языка и переводить на другой язык. Алгоритмы машинного перевода используют многие пользователи и компании, в недавнем времени появилась тенденция переводить необходимую компаниям документацию автоматически, а потом сажать людей, менее квалифицированных чем переводчики, править ошибки модели. Область быстро растет и развивается. Наша задача - взять на вход последовательность слов одного языка и сгенерить последовательность слов из другого языка.
Как понять, что мы молодцы?
Допустим, мы построили некий черный ящик, который умеет брать предложение на одном языке и переводить на другой. Также у нас есть набор тестовых эталонных переводов. Мы хотим понять, правильно ли мы все сделали. Есть два варианта.
- Люди
Самый очевидный, но и самый ресурсоемкий - посадить людей смотреть на результат машинного перевода. Часто в таких исследованиях люди проставляют оценки от 0 до 9 информативности - отображает ли перевод смысл оригинала, и разборчивости - насколько это можно и небольно читать. Такой прямой метод это долго и дорого - хочется, как и везде, обойтись без людей.
2. Автоматический расчет
Для того, чтобы быстро и бесплатно все считать, был придуман набор специальных метрик. Самая популярная из них BLEU - усредняем встречаемость n-gram между истинным переводом и переводом алгоритма. Например у нас есть предложение истинного перевода(референса) ‘I want eat’ и сгенерированного перевода(кандидата) ‘I eat’. Сначала посчитаем количество совпавших униграмм в кандидате по отношению к референсу. Оба слова из кандидата ‘I’ и ‘eat’ встречаются в референсе. Среднее по ним - 1. Перейдем к биграмме ‘I eat’. Она не встречается ни разу - среднее 0. Далее сложим логарифмы полученных значений(вместо логарифма от 0 берем 0) со весами, которые исторически определились из соображений корреляции метрики с оценкой людей. Например было установлено, что 4-граммы особенно сильно соотносятся с оценкой людей, поэтому среднему от 4-грамм дается больший вес. BLEU хорошо коррелирует с оценками людей, но есть более продвинутые метрики, которые учитывают ее недостатки. Например, NIST вознаграждает модель за корректный перевод редких слов, как и UBLEU, которые вознаграждают еще и за за корректный перевод синонимов. Есть и другие идеи, которые легли в основу метрик, например, TER (Translation Edit Rate) - считает минимальное количество исправлений, которые нужно совершить для получения корректного перевода, нормированный на размер предложения. Подробней о метриках с формулами, преимуществами и недостатками можно почитать тут - https://arxiv.org/pdf/1601.02789.pdf
Классика или seq2seq без наворотов
Seq2seq, как легко понять из названия - это архитектура, позволяющая переводить одну последовательность в другую. Один из стандартных способов обработки последовательностей - это реккурентные сети.
Краткий ликбез по реккурентным сетям
Реккурентные сети умеют брать на вход последовательность слов произвольной длины и делать из них один вектор, учитывая очередность слов и запоминая важную информацию по ходу последовательности. Делается это следующим образом - слово преобразуется в вектор(в простом случае - с помощью one hot encoding, в сложном - вектор полученный с помощью использования семантической информации из большого набора текстов(word2vec, fasttext). Затем представление каждого вектора(x на рисунке 1) передается в ячейку реккурентной сети вместе с вектором состояния от прошлого слова - память от каждой предыдущей ячейки, в которой хранится важная информация от всей предыдущей последовательности. Для первого слова нет предыдущего, поэтому этот вектор инициализируется случайно. На выходе из ячейки выдается некое предсказание, например вероятность текущего слова при условии всех предыдущих(h на рисунке 1), сеть вычисляет, что нужно запомнить, а что забыть, преобразует эту концепцию в вектор скрытого состояния и передает его дальше.
Часто используют двунаправленные реккурентные сети - где мы добавляем скрытые состояния, которые передаются в обратном направлении.

Вернемся к архитектуре seq2seq. Seq2seq состоит из энкодера и декодера.
- Энкодер отвечает за, чтобы представлять входящую информацию от текста, которое мы переводим, декодер - за то, чтобы генерить перевод. Во время обучения энкодер берет на вход последовательность слов из одного языка и генерит вектор, который представляет всю эту последовательность. Во время обучения и применения энкодер ведет себя одинаково.
- Декодер. Для предсказания каждого слова перевода, декодер берет на вход вектор из энкодера, предыдущее слово перевода и выдает вероятность выдать текущее слово. Во время обучения мы оптимизируем правдоподобие - вероятность перевода при условии оригинального предложения. Во время применения и обучения модели декодер работает по-разному. Разница между декодером на стадии обучения и применения в том, что на стадии обучения декодер предсказывает вероятность текущего слова при условии предыдущих с учетом слов, которые реально были до этого, на стадии применения декодер основывается на своих же предсказаниях. Часто это бывает проблемой, потому что если мы предсказали неправильное слово, потом мы протаскиваем эту ошибку на все слова после этого. Частично поправить эту проблему позволяет beam-search, о котором речь пойдет в следующем разделе.

Decoder+beam-search = счастье
Итак, на этапе применения модели, когда мы предсказываем слово на выходе из декодера, можно сделать все просто и выбрать слово, которому сеть дала наибольшую вероятность. Но это не совсем хорошо. Приведем пример. Мы переводим предложение ‘Хочу что-то понять в этом конспекте’ с русского на английский. Допустим, слово ‘хочу’ сеть перевела, как ‘want’ с вероятностью 0.44, и как ‘should’ с вероятностью 0.45. Тогда мы выберем на первом шаге первым же словом неправильный перевод, что потянет за собой череду ошибок, хотя истина была близко. А вот если бы мы про запас оставили несколько самых вероятных вариантов, посчитали бы вероятности следующих слов, опять оставили бы несколько вероятных вариантов, а потом выбрали бы самую вероятную в совокупности последовательность слов, то качество перевода бы заметно улучшилось. Эта идея и носит название beam-search и активно применяется в машинном переводе.
Немного поумней seq2seq + attention
В чем была проблема?
Классическая архитектура seq2seq хороша, но имеет существенный минус - если предложение, которое мы хотим переводить, достаточно длинное, то одного вектора на выходе из энкодере нам может быть мало, чтобы хорошо восстановить всю информацию, которая содержится в оригинале текста. Также часто в разных языках(например, в английском и русском) используется разный порядок слов в предложении. Возьмем к примеру предложение на русском ‘На улице холодно’ и его перевод на английский ‘It’s cold outside’. Если бы при предсказании слов мы использовали стандартную модель seq2seq, то значительная часть информации об улице, которая идет в начале предложения на русском, к английскому слову outside, который находится в конце перевода потерялась бы.
Как решать проблему?
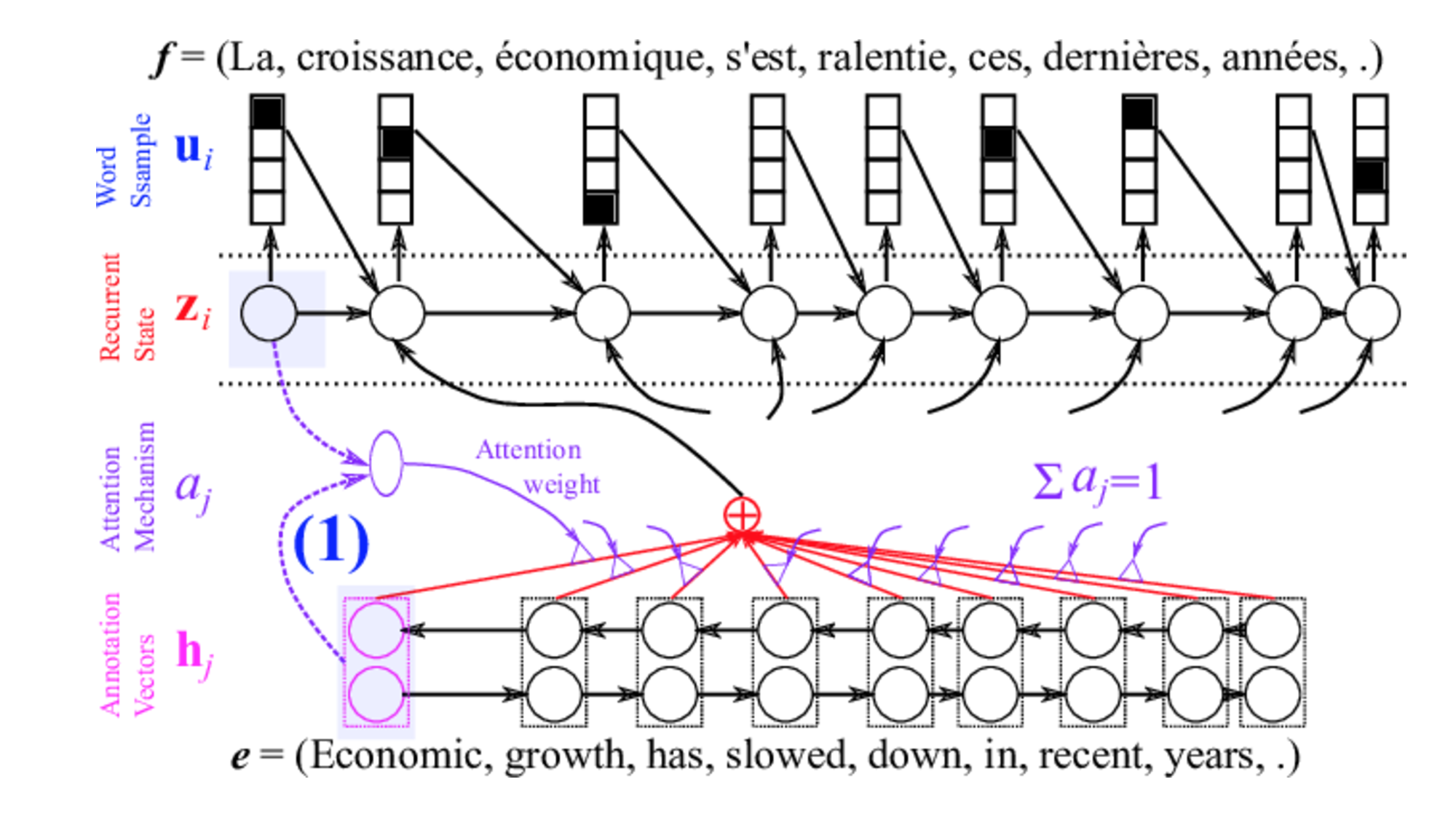
Поэтому разумно научить декодер не просто обращаться к финальному скрытому состоянию энкодера, а к взвешенной сумме скрытых состояний энкодера в каждом моменте времени - это дает нам заметно больше гибкости. Веса, с которыми будем складывать эти состояния мы учим отдельного для каждого слова в декодере. Нужно это для того, чтобы понимать на какую часть предложения в энкодере стоит обращать внимание декодеру. Таким образом attention позволяет нам обращать внимание на нужную часть предложения и предоставляет большую гибкость и большее количество полезной информации в решении задач машинного перевода. Пример того, как выглядит архитектура attention в применении к энкодеру двунаправленной реккурентной сети, можно увидеть на рисунке 3.
А может вообще без RNN? Attention is all you need!
Теперь посмотрим в прошлое и заметим, что все обсуждаемые до этого архитектуры использовали реккурентные сети. У них есть один большой недостаток - их крайне сложно параллелить, так как нужно знать предыдущие скрытые состояния и вероятности слов, чтобы генерить следующие слова. Хочется придумать какую-то архитектуру, которая учитывала бы взаимосвязь слов (как реккурентные сети) и могла бы эффективно параллелиться.
На помощь приходит идея архитектуры Transformer, которая бьет SOTA(State of the art) по метрике BLEU на данной задаче. Смысл состоит в следующем:
- Энкодер. На вход энкодеру по-прежнему подаются эмбеддинги для слов языка оригинала, для каждого слова в эмбеддинг прибавляется еще и номер слова в последовательности (positional encoding). Мы хотим получить из них всех вектора для каждого слова, которые хорошо передают связь слов и особенности текста. Делаем это с помощью Multihead Attention. Для каждого входного слова считаем близость со всеми другими словами - это веса, с которыми мы прибавляем остальные слова к исходному, получая таким образом новый эмбеддинг для входного слова. Но похожесть бывает разная - лексическая, семантическая(внутри семантической есть также очень много смыслов), поэтому такие веса мы учим несколько раз, полученные суммарные вектора для всех весов пропускаем через сетку и получаем финальный эмбеддинг для каждого входного слова. Этот эмбеддинг отражает номер слова в последовательности и его взаимоотношения со всеми другими словами. Эмбеддинги для всех слов засовываем еще в одну сетку с residual connections и получаем финальный эмбеддинг для слов.
- Декодер. Мы берем на вход эмбеддинги для слов энкодера, применяем к ним архитектуру multihead attention, также берем предыдущие слова из декодера, также обработанные multihead attention и предсказываем следующее слово. Архитектуру энкодера и декодера можно посмотреть на рисунке 4. Подробней про архитектуру Transformer можно почитать в статье https://arxiv.org/pdf/1706.03762.pdf

Жизнь без обучающей выборки
Теперь попробуем посмотреть на задачу машинного перевода совсем с другой стороны. Известно, что хорошая обучающая выборка для перевода есть далеко не для всех пар языков. Также данные по переводу новых, специфичных текстов на профессиональные темы появляются заметно более медленно, чем сами тексты. Поэтому в идеальном мире мы бы очень хотели уметь переводить набор текстов с одного языка на другой совсем без обучающей выборки.
Это и осуществили авторы статьи Unsupervised Machine Translation Using Monolingual Corpora Only(https://arxiv.org/abs/1711.00043), не катастрофически отстав по BLEU от методов обучения с учителем. (сравнение с другими алгоритмами - Таблица1)

Основная идея алгоритма заключается в следующем. Допустим, мы хотим научиться переводить тексты с русского языка на английский. На входе у нас есть набор текстов на русском и английском без соответствия друг другу. Сделаем два автоэнкодера, первый из которых умеет брать русский текст на вход, преобразовывать в сжатое латентное пространство, а из него уже восстанавливать тот же русский текст, и такой же автоэнкодер для английского языка. Предположим, что есть некое общее латентное смысловое пространство для русского и английского, и будем пытаться приводить латентные пространства из русского и английского автоэнкодеров в это общее пространство. Для этого поставим на вход в эти пространства дискриминатор, который будет штрафовать энкодер, если у него получится определять, сжатое представление каких данных - русских или английских пришло ему на вход. Когда мы добились того, что дискриминатор не может определить русские или английские данные мы ему кормим, поменяем местами декодеры в этих автоэнкодерах и получим два переводчика сразу - с русского на английский с английского на русский!

Рисунок 5. Устройство unsupervised MT модели
Transfer learning на задаче Machine Translation
В задачах машинного обучения на картинках и текстах распространено использование предобученных моделей. Например, в компьютерном зрении часто используют тяжелые сетки, обученные на огромных датасетах, чтобы из них достать признаки для картинок. Transfer learning занимается тем, что меняет переносит разработки с одной задачи на другую. В открытом доступе есть большое количество переведенных данных, на которых можно натренировать модель seq2seq, и взять представления слов в энкодере, как эмбеддинги, которые хорошо представляют контекстную информацию. Что и сделали авторы статьи Learned in Translation: Contextualized Word Vectors(https://arxiv.org/pdf/1708.00107.pdf) , побив SOTA по ряду NLP задач (информация актуальна до выхода алгоритма ELMO (https://arxiv.org/abs/1802.05365) в феврале 2018 года).

Рисунок 6. Схема Transfer learning с помощью MT
Что в итоге
Машинный перевод - очень классная и интересная задачка, в которой много всего можно улучшать. Из основных направлений для улучшений - скорость работы, интеграция с другими задачами, перевод без учителя