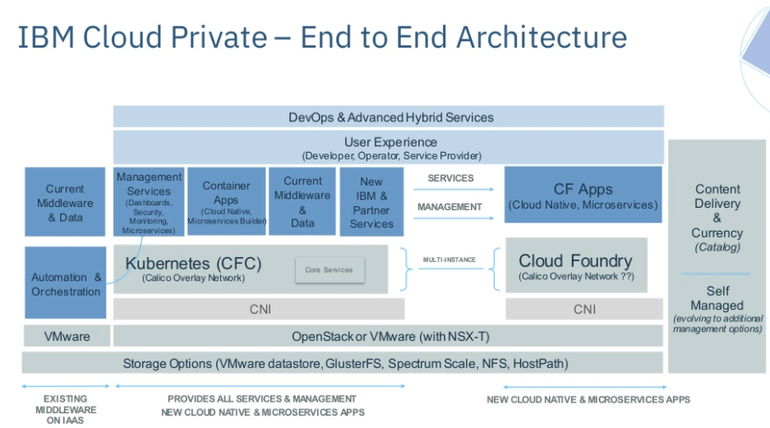
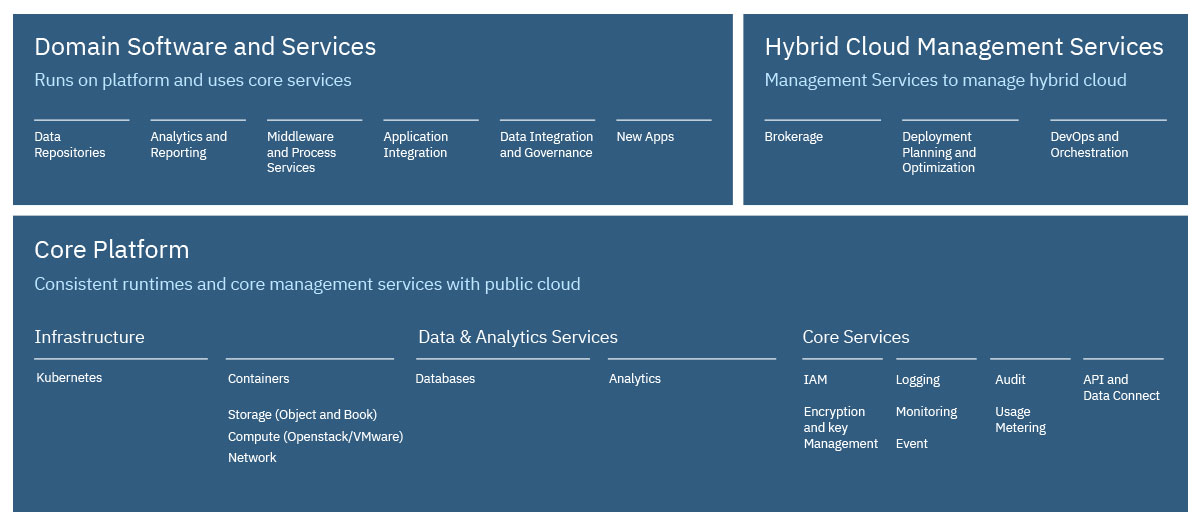
IBM Cloud Private : déployer Kubernetes dans un Cloud privé et porter le datacenter au plus près des technologies dites Cloud Natives ...
KarimIBM a transformé son produit anciennement nommé IBM Spectrum Conductor for Containers Community Edition en IBM Cloud Private intégrant Kubernetes ( gratuitement dans cette version communautaire et bien entendu Open Source).

Et en ayant la possibilité de le coupler avec Cloud Foundry le cas échéant :
Je réalise un petit autour d'IBM Cloud Private en partant d'un serveur physique chez Scaleway :
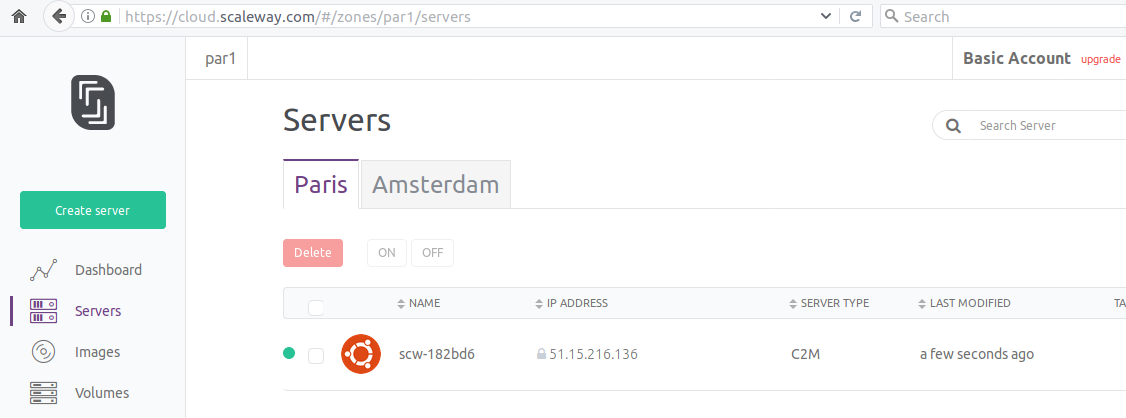
J'ajoute un second disque physique de 100 Go en plus du disque principal à 50 Go pour respecter les minimas en terme d'exigences techniques liés au déploiement ici en mode minimaliste d'IBM Cloud Private :
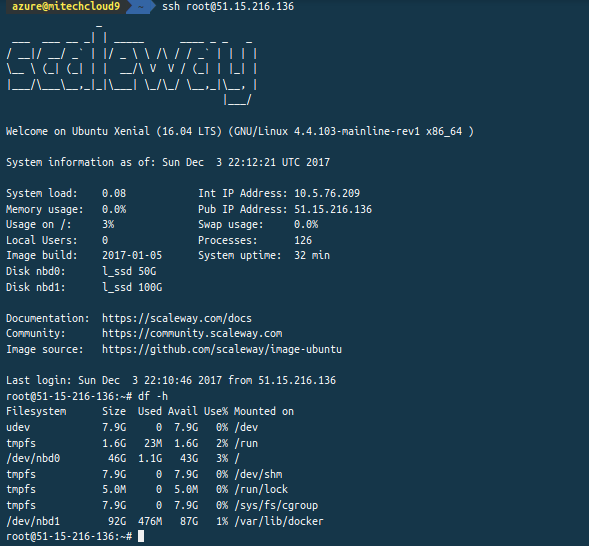
Je lance un container Docker conteant une série de playbooks Ansible et qui va me servir ici de déployeur :
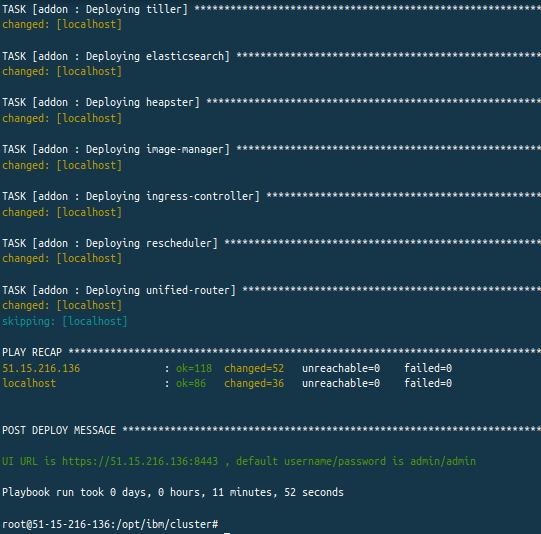
Une fois l'exécution des playbooks terminés je reçois un lien d'accès à la console d'IBM Cloud Private :
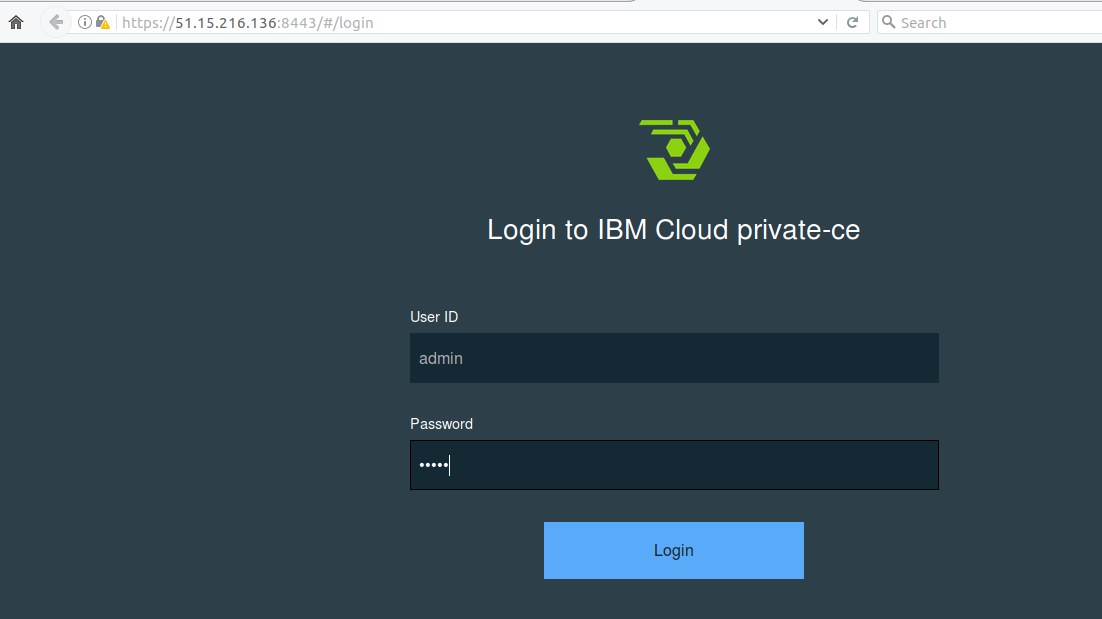
avec les principales métriques de santé de la plateforme :
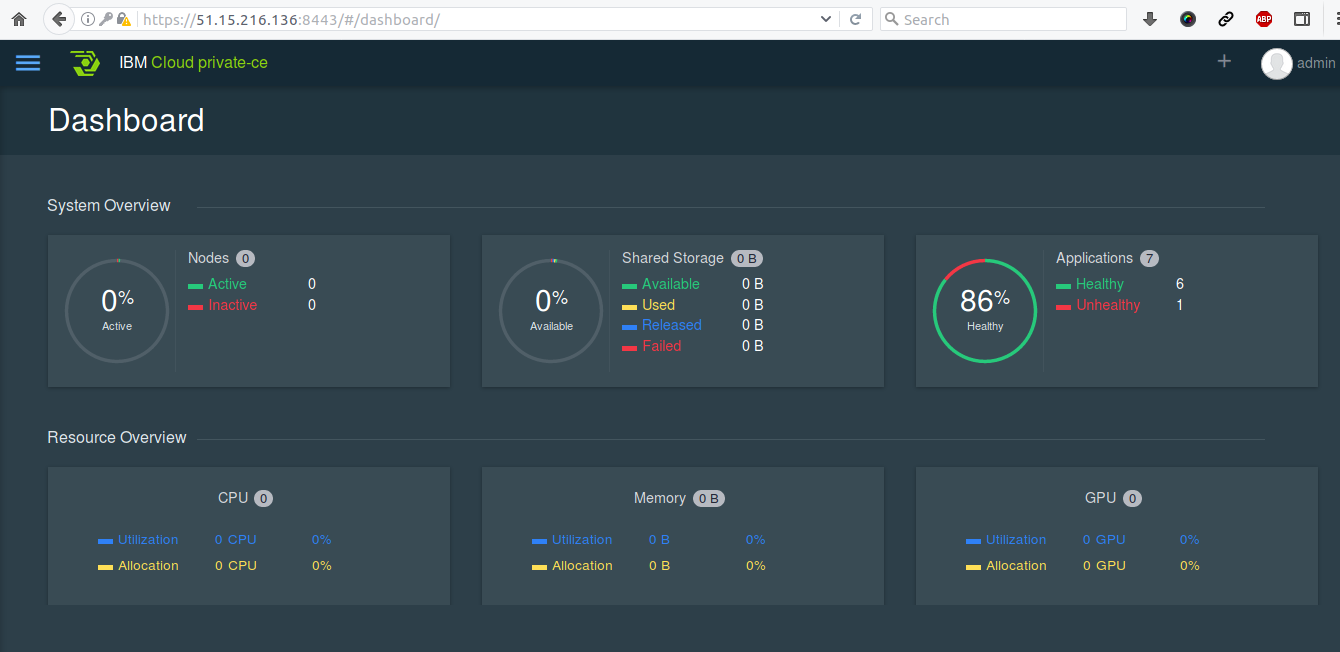
et des sous menus graphiques pour faciliter la prise en main de Kubernetes (la plupart du temps contrôlable par les lignes de commande) :
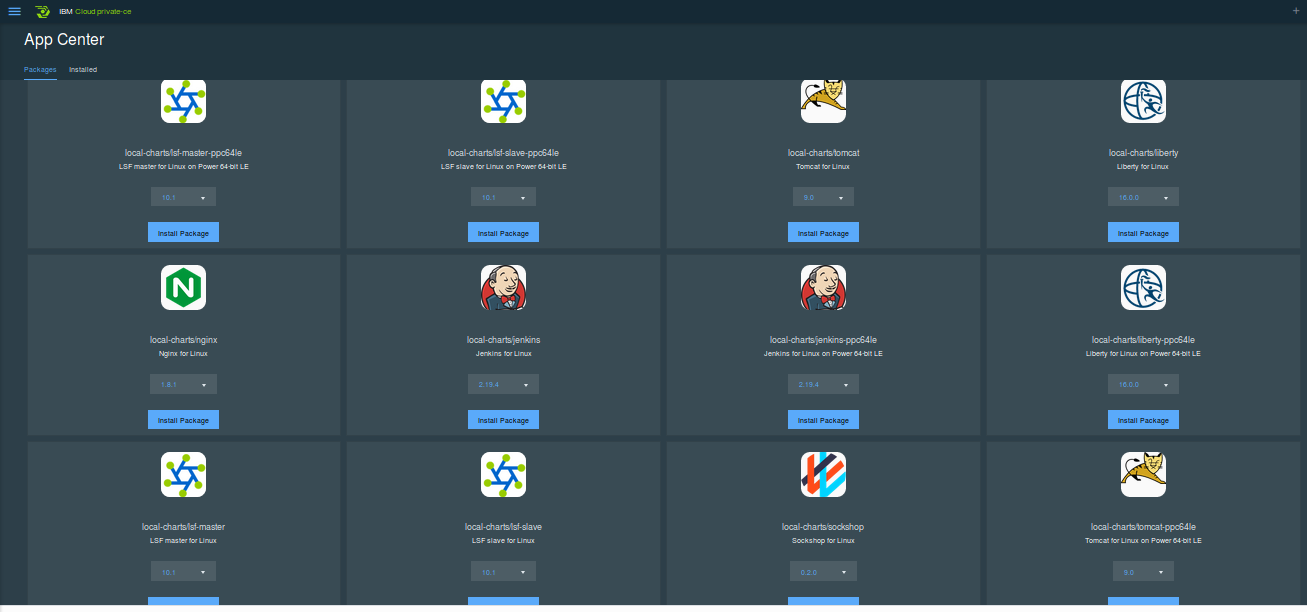
avec un marketplace peuplé via Helm (et que l'on retrouvait déjà via Bitnami dans kubeapps.com) :
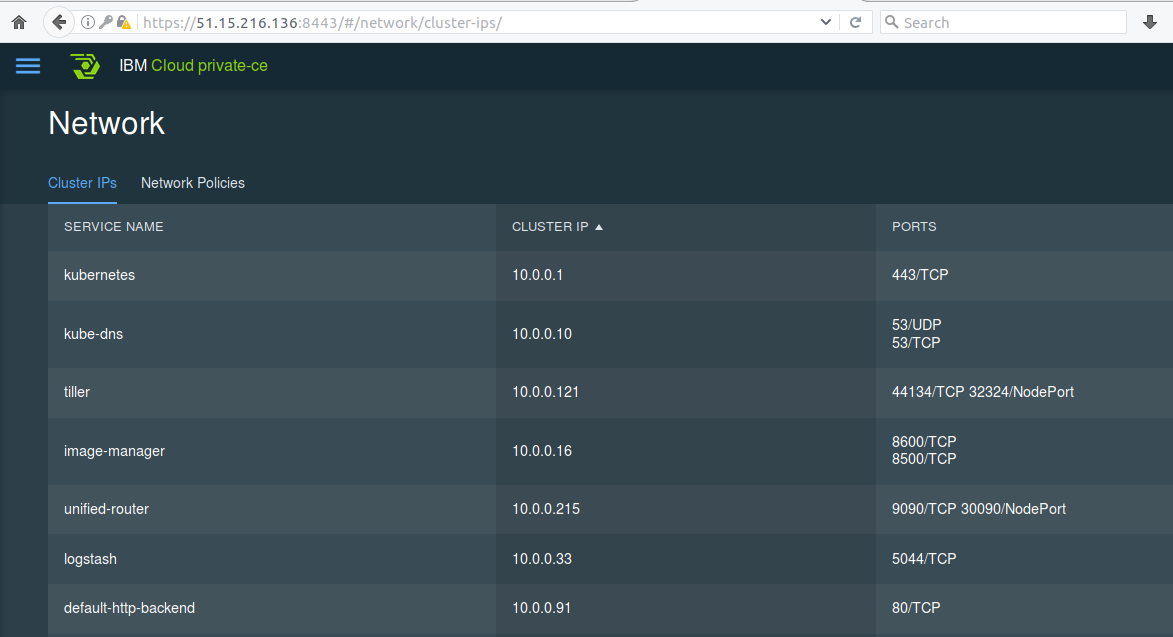
le software defined networking pour les containers via Calico (initialement de Cisco) :
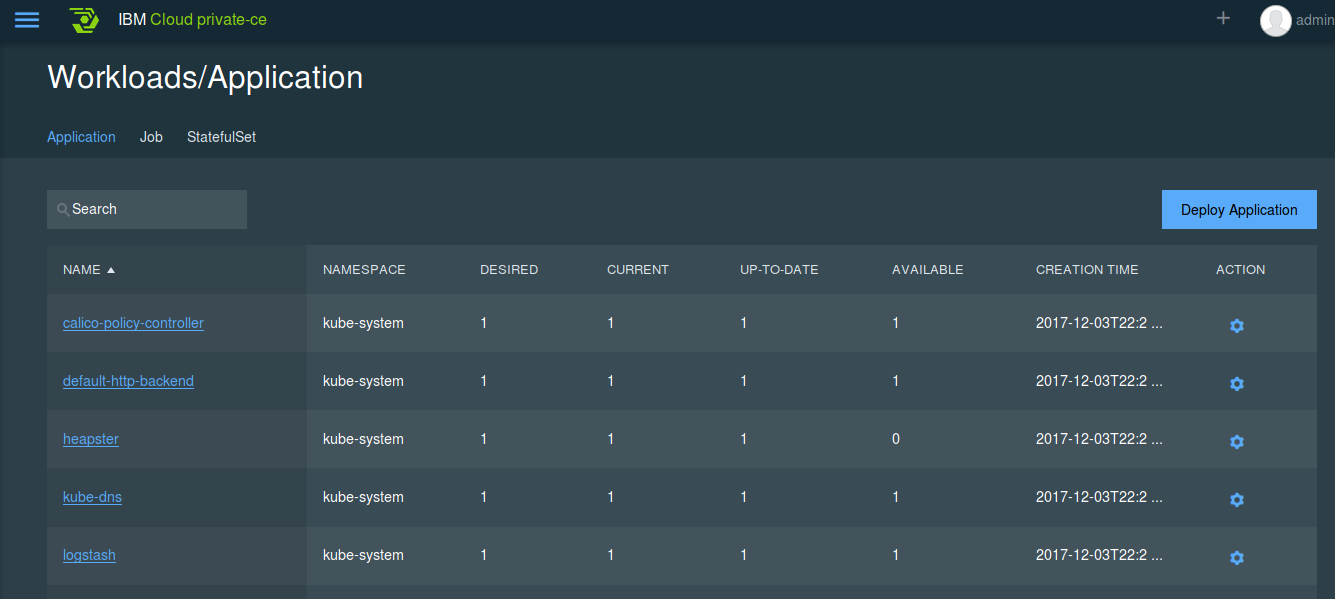
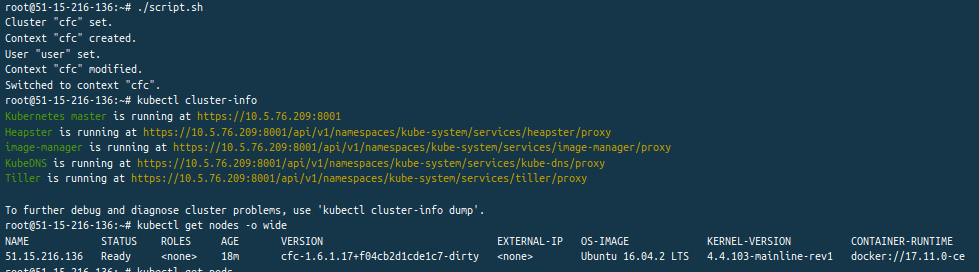
mais encore une fois accessible via les outils en ligne de commande :

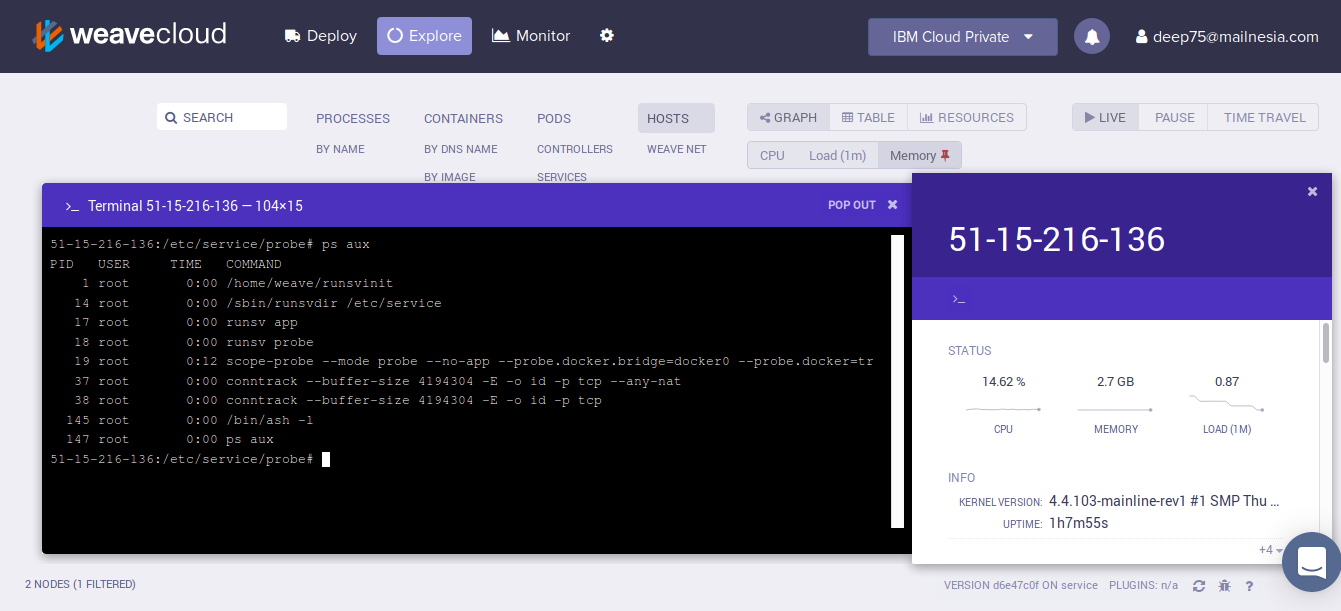
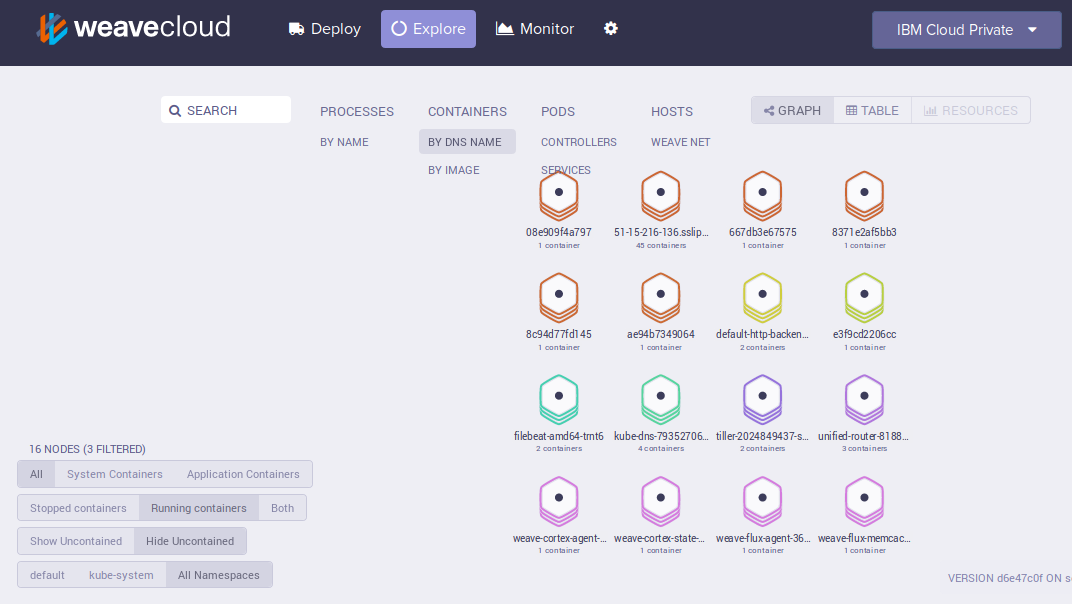
J'ai la possibilité comme auparavant de monitorer la plateforme via Weave :
et je lance un rapide test de CI/CD avec Jenkins dans IBM Cloud Private :

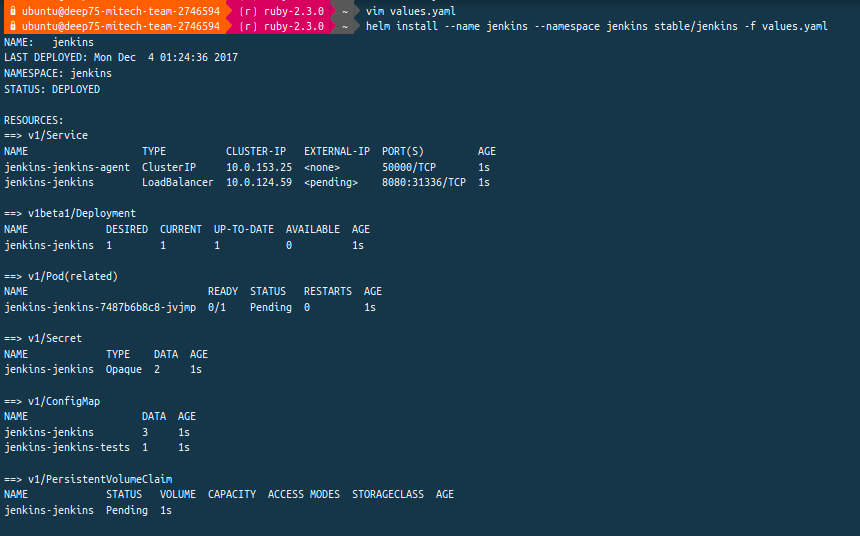

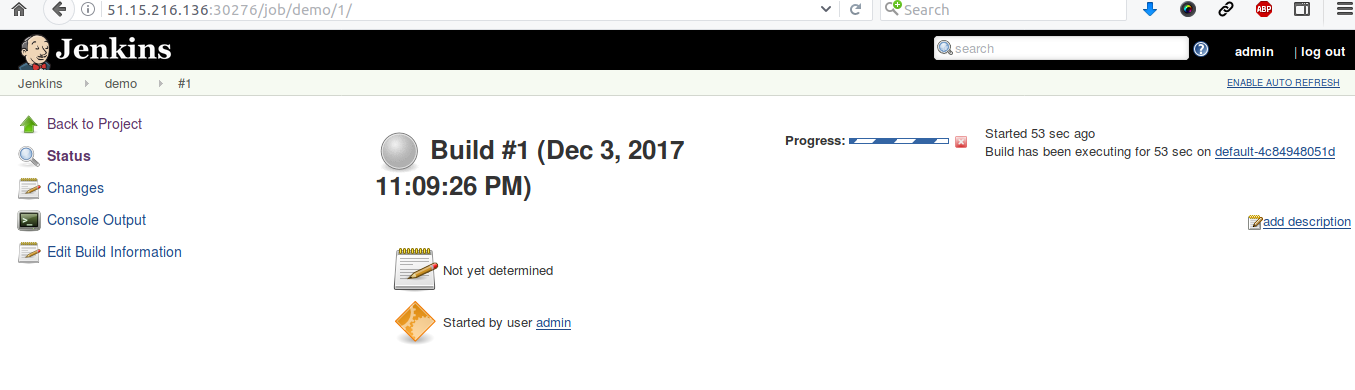

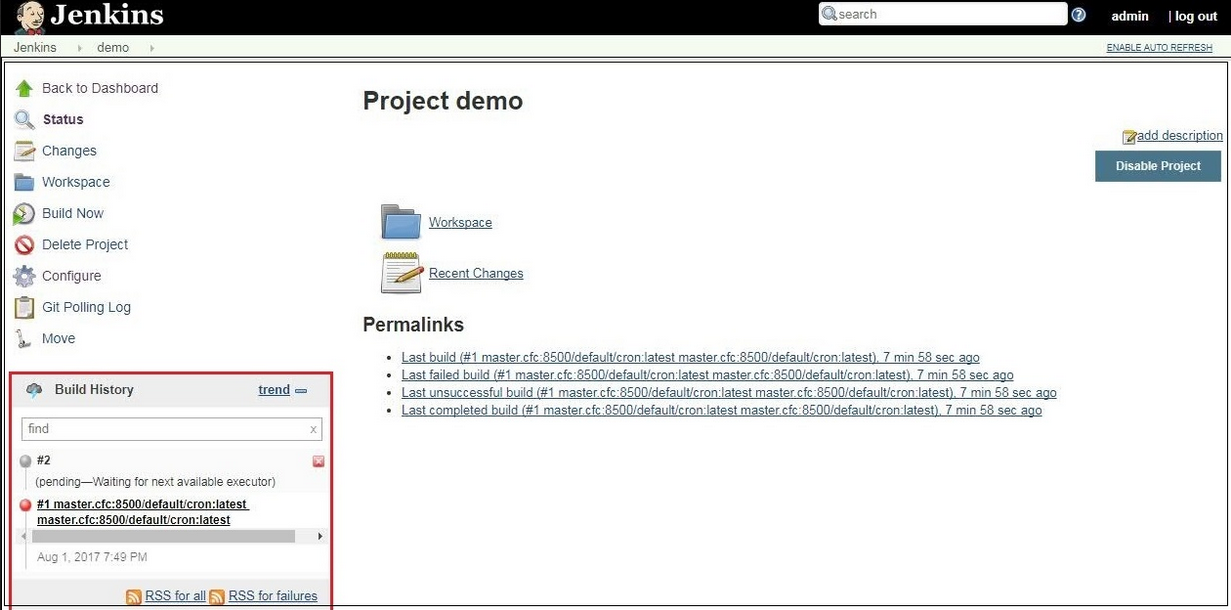
Je peux également lancer un cluster avec plusieurs noeuds ici en utilisant les machines d'Outscale :
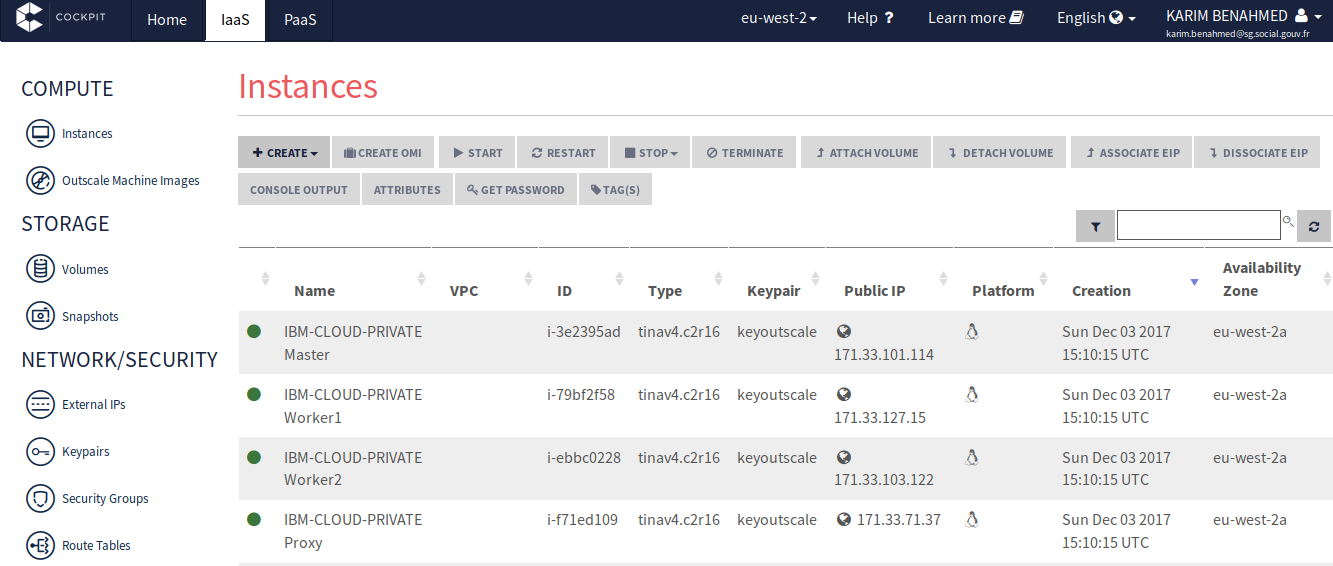
Idem via les playbooks Ansible embarqué dans ce container de déploiement :

et j'accède alors à la dernière version 2.1.0 d'IBM Cloud Private :

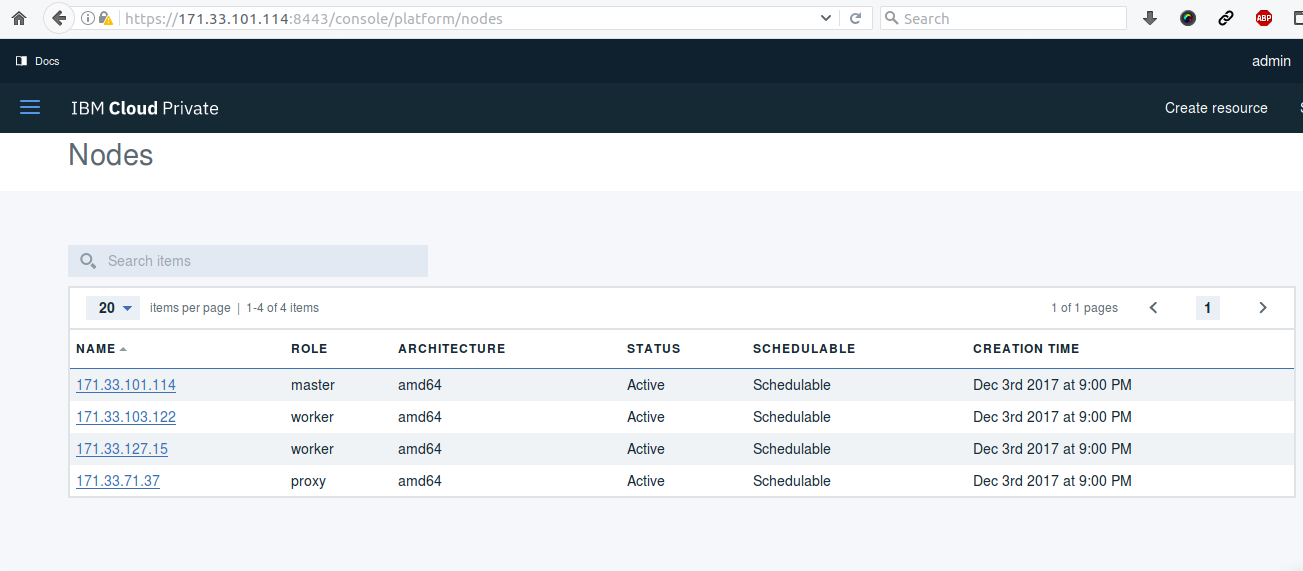
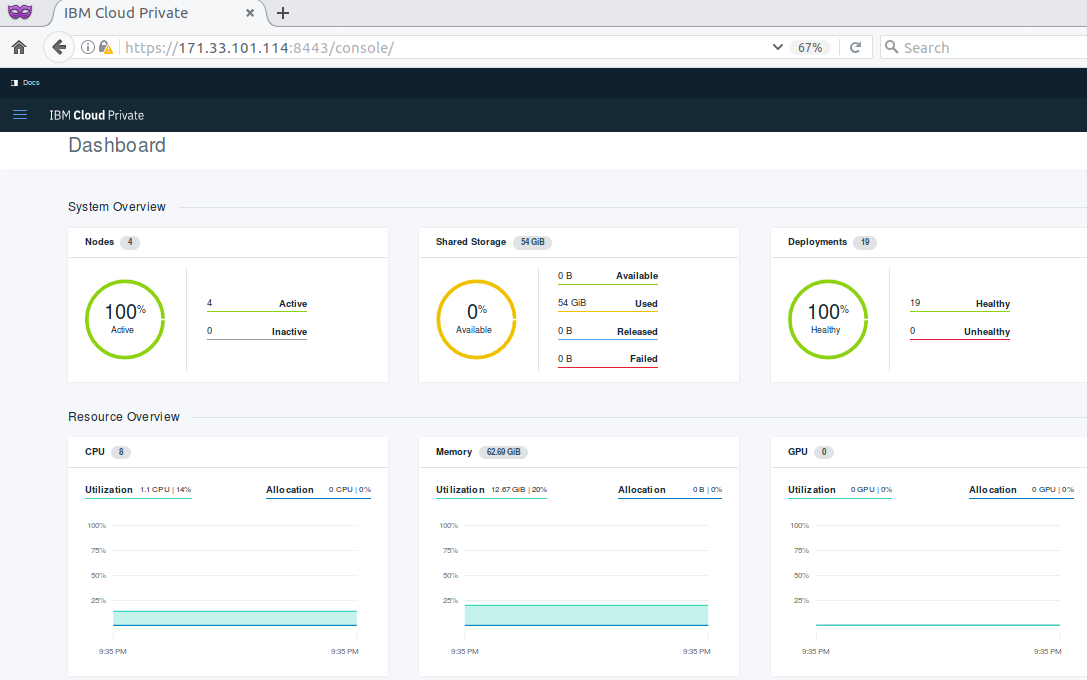
et les CLI toujours disponibles :
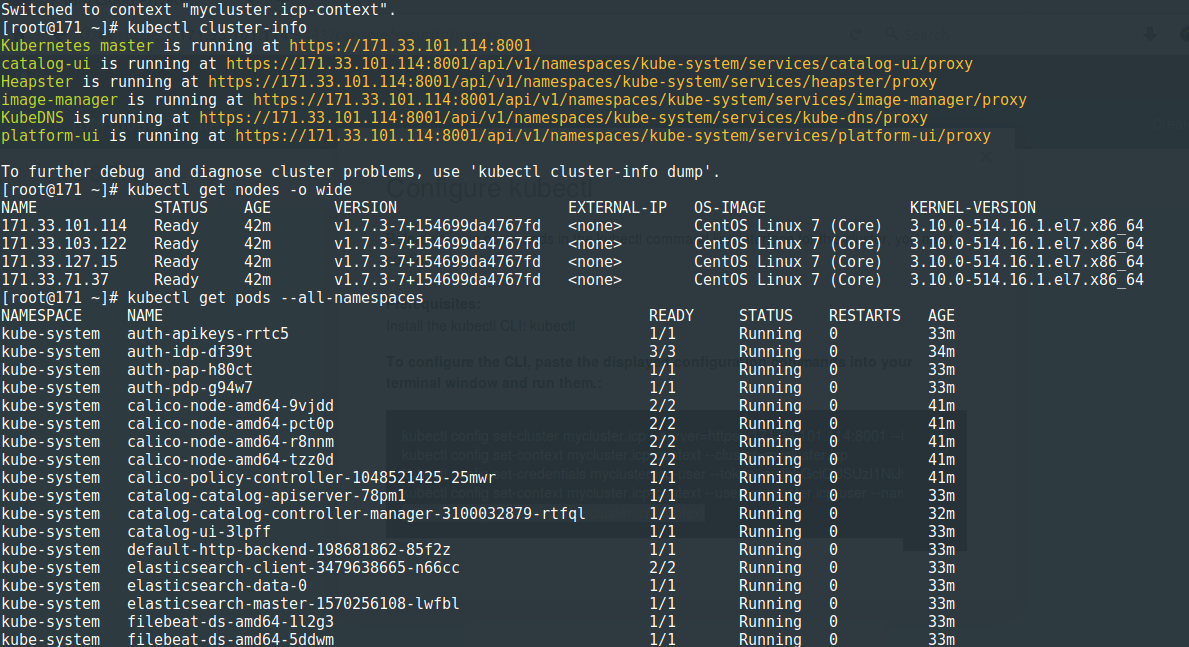

et plusieurs repositories de Charts Helm que l'on peut rajouter pour alimenter son marketplace :
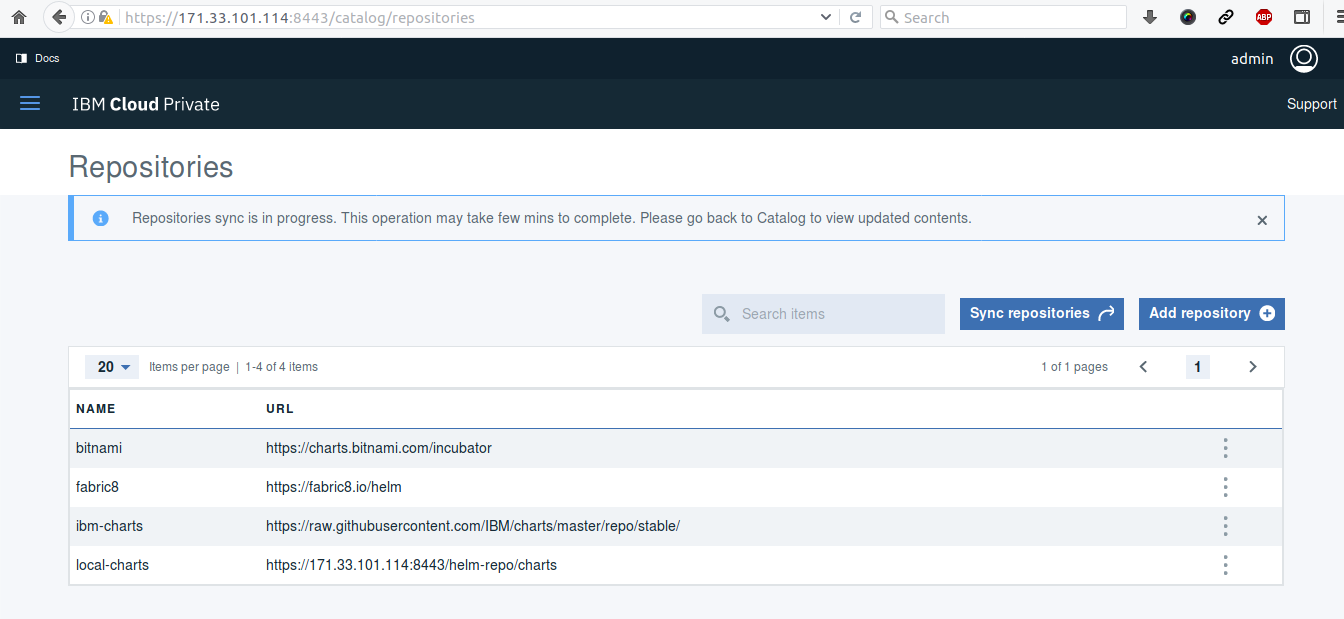
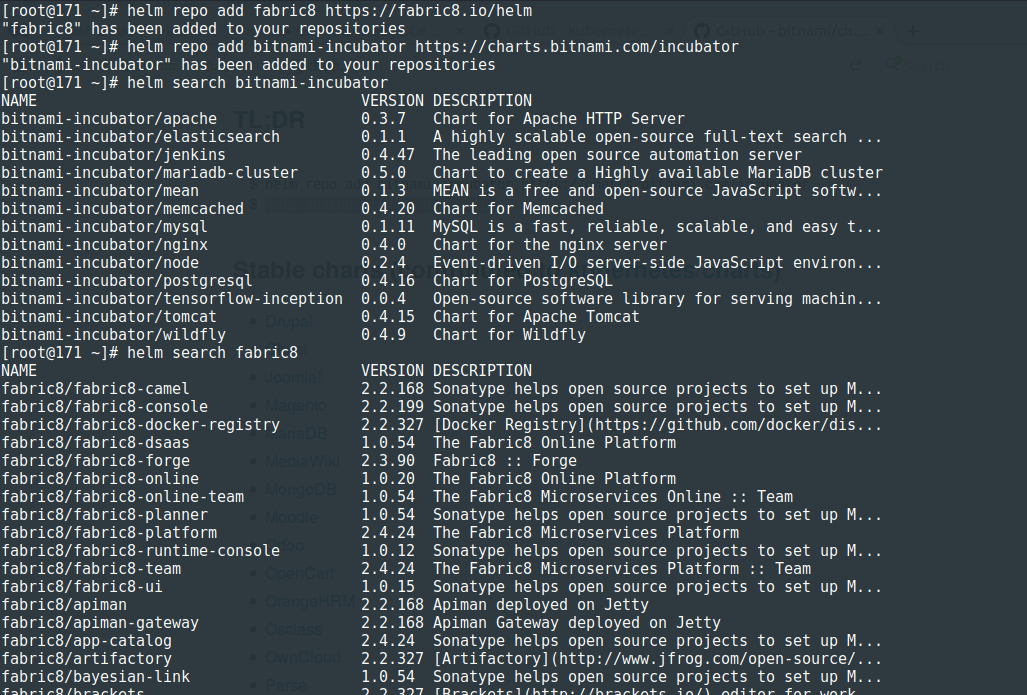
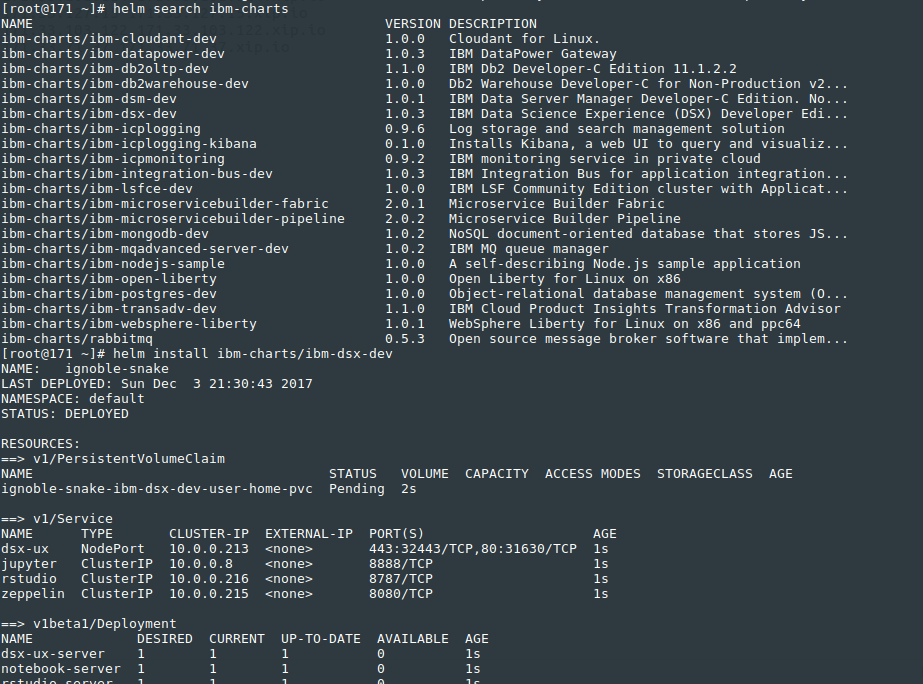
Je termine en corrolaire par l'Azure Distributed Data Engineering Toolkit (AZTK) qui sont des outils python pour le provisioning à la demande de clusters Spark sur les clusters Docker dans Azure. Rapide test :
lancement en ligne de commande via Python :
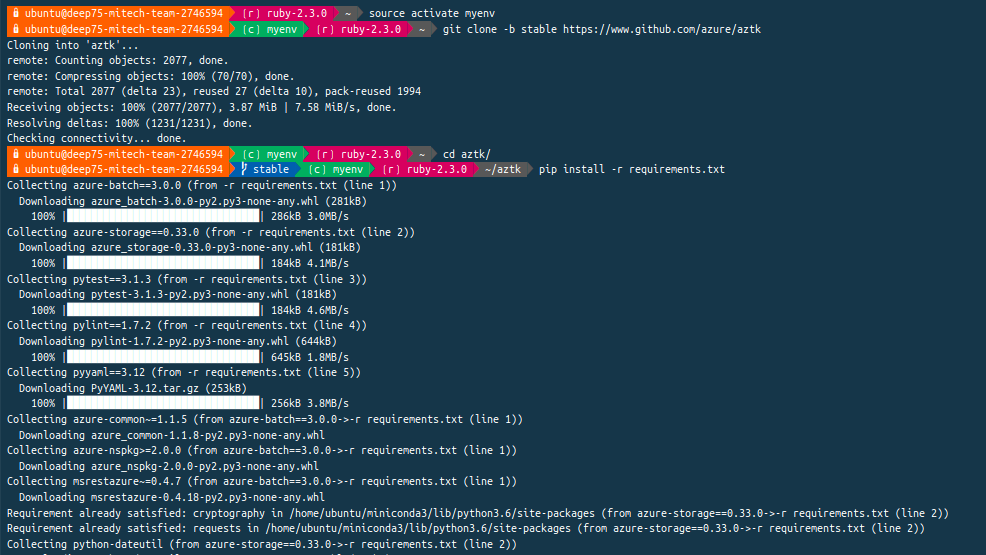
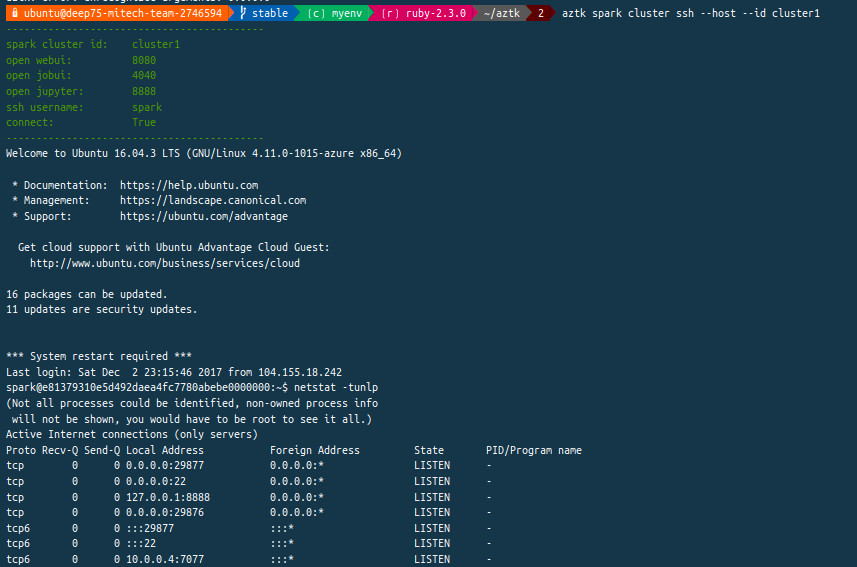
Je lance ce cluster Spark sur la base de VM équivalentes aux Spots Instances dans AWS ou aux Premeptibles VMs dans Google Cloud, c'est à dire des VMs éphémères (autrement à moindre coût comparées aux VMs classiques) :
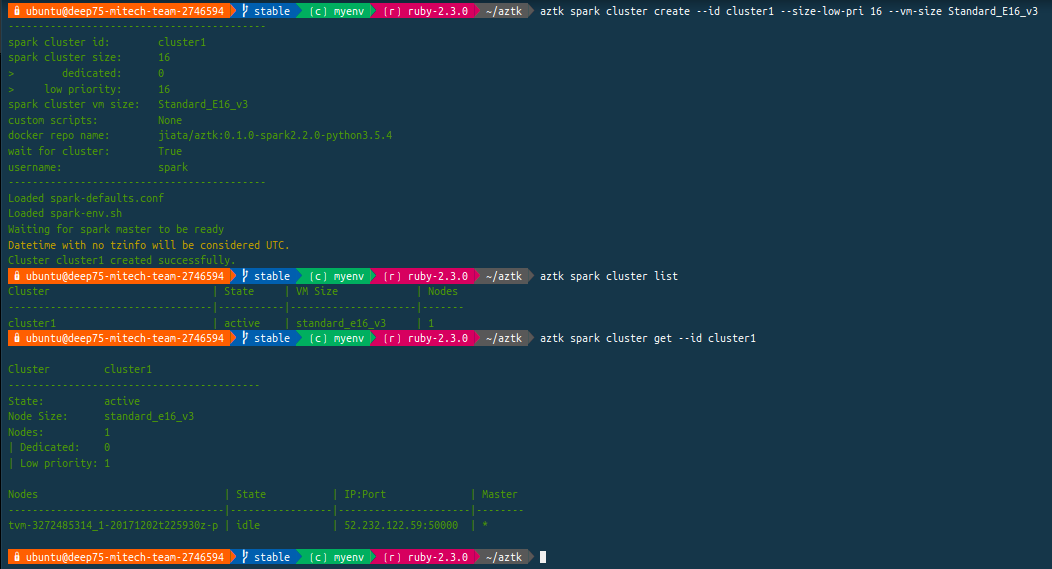
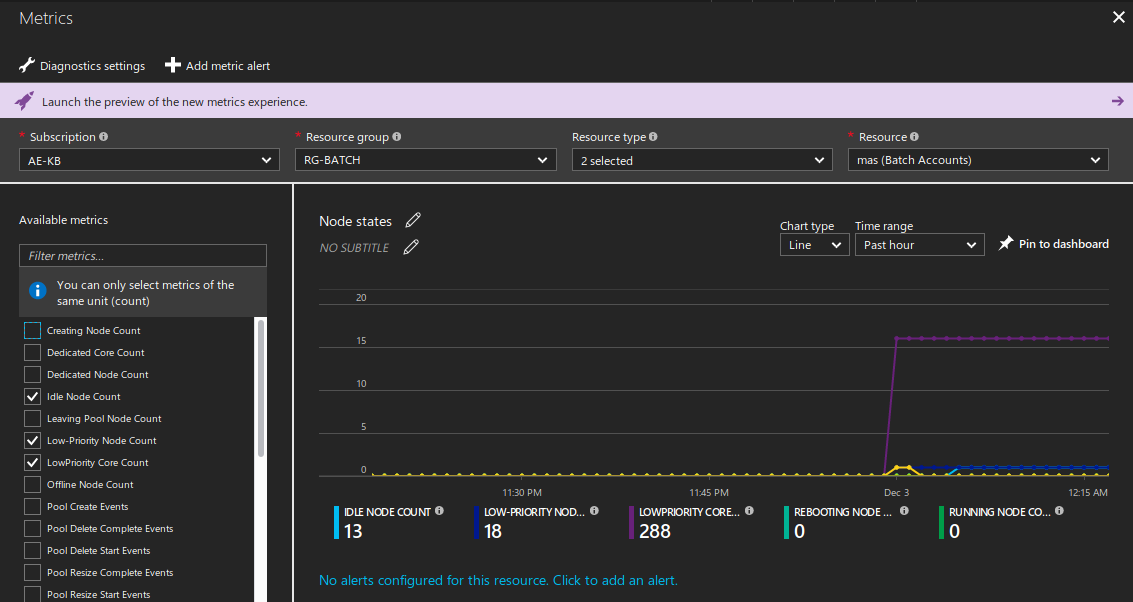
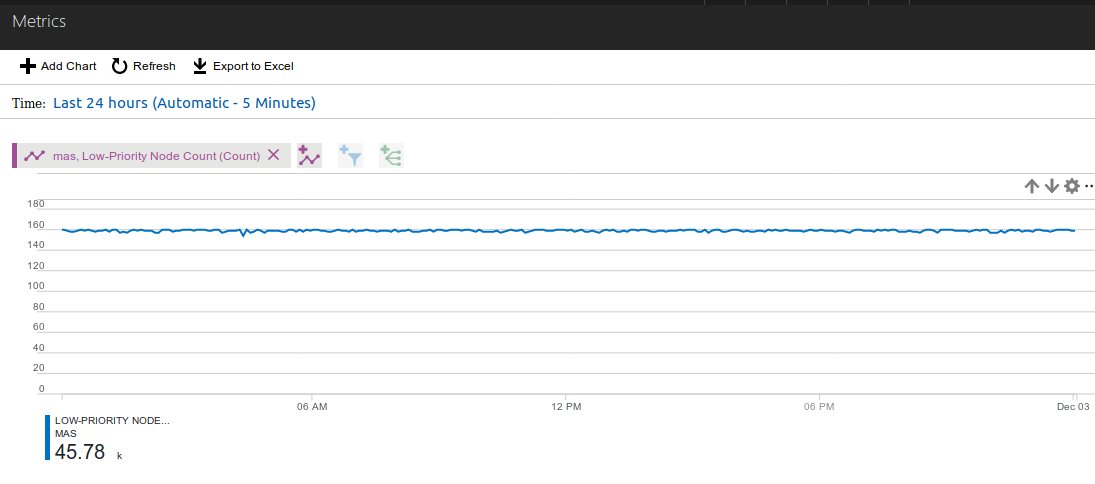
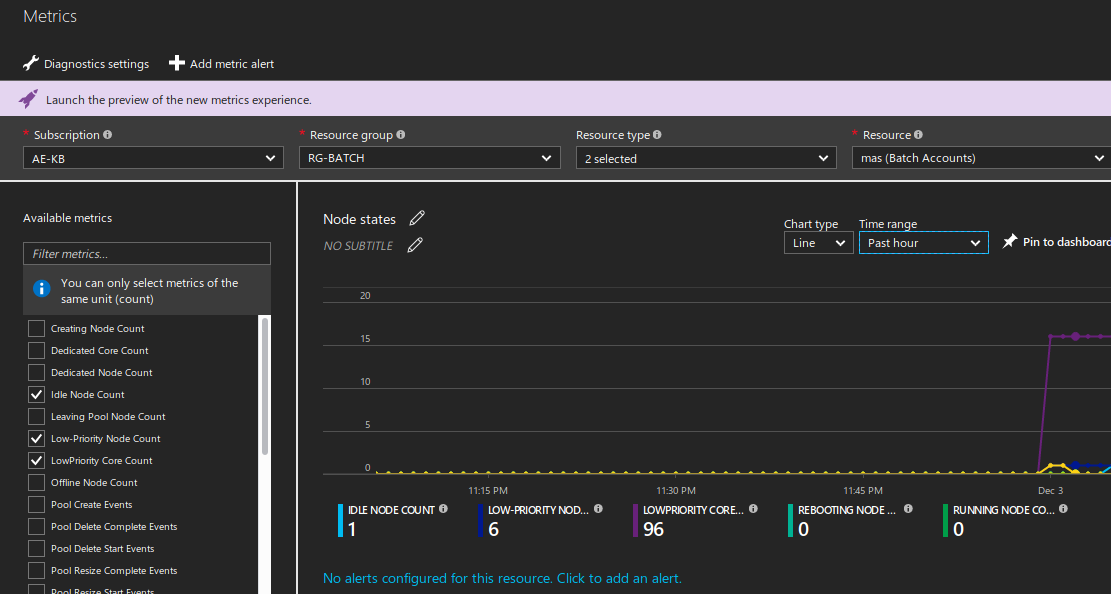
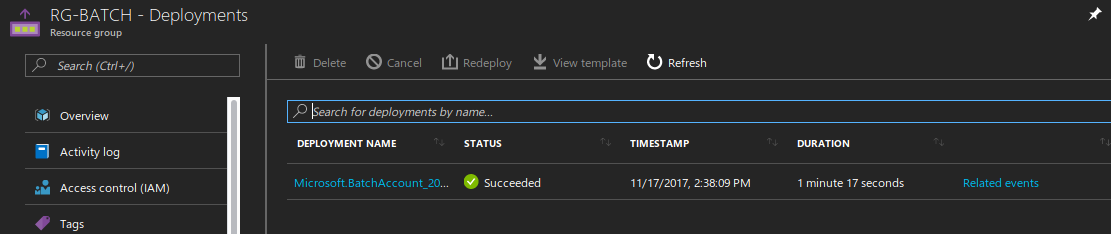
on retrouve Microsoft Azure Batch en arrière fond couplé à Azure Storage :
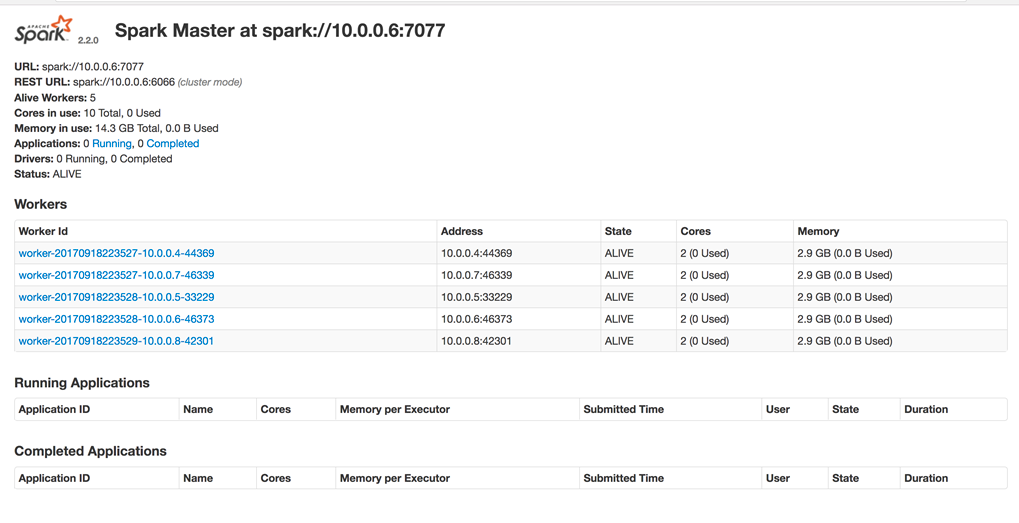
avec le dashboard du Spark Master :
et sa suppression après lancement de ses batchs est tout aussi simple :

A suivre ! ...