A propos des grandes distributions Hadoop (Cloudera, Hortonworks, MapR et consorts) ...
KarimCe sont mes derniers jours aux ministères sociaux donc je termine par un petit tour d'horizon des grandes distributions dédiées au Big Data ...

qui se tiennent très près l'une de l'autre dans le champ du Big Data (à la compétition intense) :

Je commence par Cloudera et sa distribution Cloudera Data Hub (CDH) open source dans Azure (avec pleins de composants Apache) ...

Cloudera proposant son mode Big Data as a Service (BDaaS) avec Cloudera Altus pour proposer des déploiements de cluster à la demande chez les grands cloud providers ...


Déploiement d'un resource group embarquant la VM Cloudera Director ...

On part d'une VM Cloudera Director qui va jouer le rôle de déployeur du cluster Cloudera Data Hub :

Je sélectionne les éléments du cluster à déployer à partir de templates CentOS prédéfinis ...

le cluster est disponible avec un dashboard abordant les principales métriques du cluster :




Je suis contrait d'utiliser une VM OpenVPN Access Server pour visualiser le dashboard du cluster Manager (il y a un plan d'adressage privé prédéfini accompagné d'un domaine local lors du déploiement du cluster) :

Je me retrouve donc avec un "petit" cluster à 43,7 To de stockage, 110 Go de mémoire vive et environs 60 CPU ...

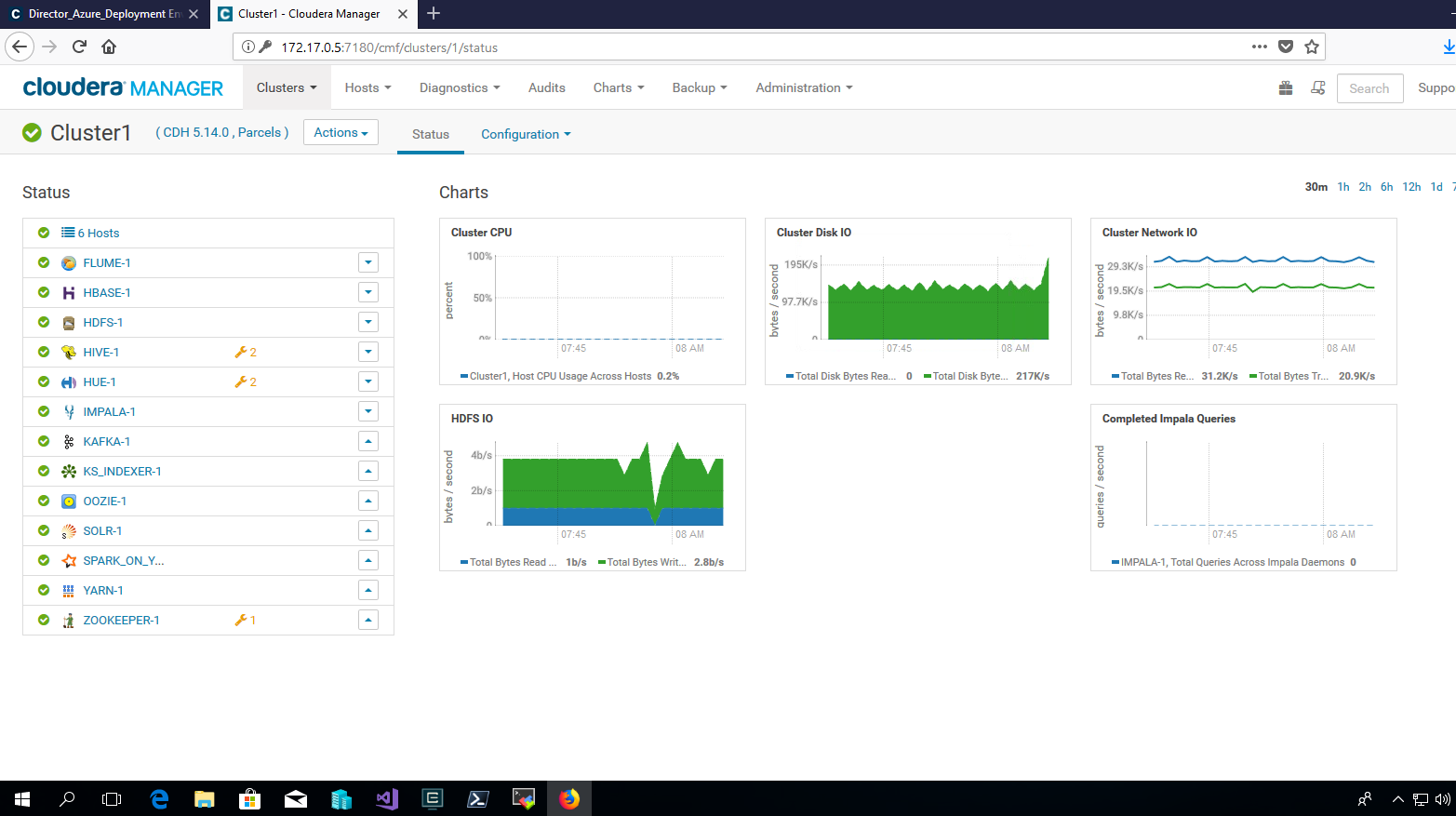
et je visualise les métriques du cluster Cloudera Data Hub dans le dashboard offert au travers de Cloudera Manager (avec ici tous les services embarqués d'Apache Flume, en passant par Apache Hive, Apache Solr, Apache Impala jusqu'à Apache Kafka et Apache Hue) ...



avec l'entrepôt de données Apache HBASE :

et le requêteur SQL dans Apache HUE (comme on l'avait vu dans Outscale avec sa brique de cluster MapR à la demande) :

Je peux me livrer à un petit exercice en utilisant JBoss Data Virtualization en le connectant à Apache Impala, gestionnaire du cluster Cloudera :





La création de cette base de données virtuelles condensant plusieurs données issues de plusieurs sources de données est effective ...

et une requête vers l'API REST de JBoss Data Virtualization via un client Postman permet de requêter sur ces données "virtualisées" ...

Je passe ensuite à l'exercice autour de MapR Converged Data Platform en mode communautaire et open source toujours dans Azure :


Je lance depuis le marketplace la création de ce cluster qui va encore une fois embarquer une VM OpenVPN Access Server :


Je me connecte au portail OpenVPN pour accéder au cluster MapR :

et je visualise les principales métriques du cluster :

Un cluster ici très simple à 3 noeuds chacuns embarquant 3 disques SSD à 127 Go :


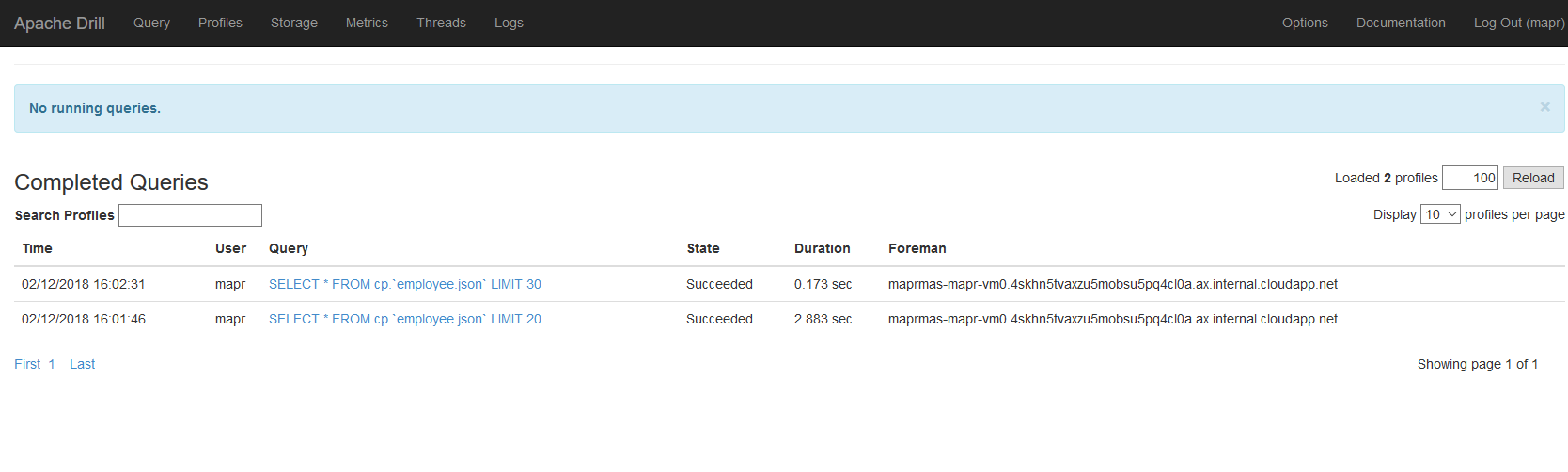
Le cluster embarque la fameuse brique Apache Drill (très inspiré de Google Big Query) pour lancer des requêtes de type SQL sur les données stockées dans le système de fichiers distribué HDFS :


Connexion au portail d'Apache Drill dans le cluster MapR :

et je peux faire un petit test de requête vers un jeu de données embarqué ...


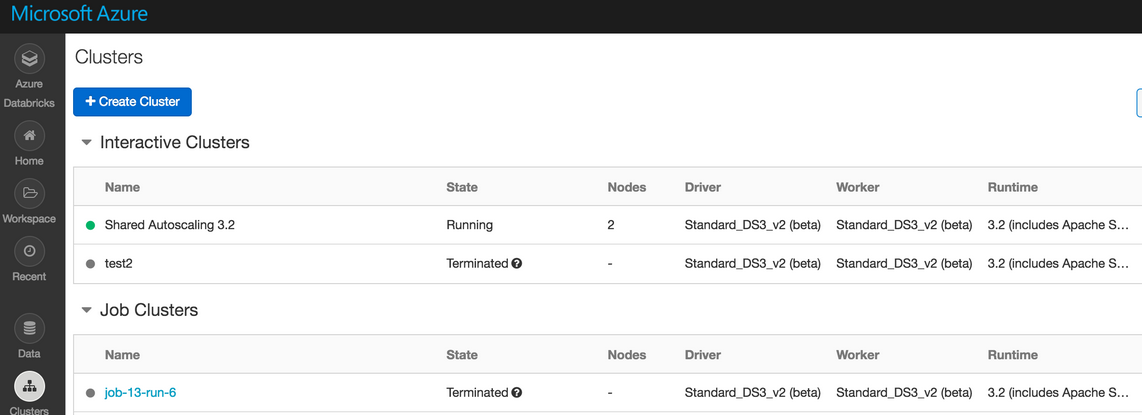
A noter que Databricks (la société qui porte principalement les développements autour d'Apache Spark et son écosystème) a proposé en preview son Databricks Workspace pour proposer des cluster Spark à la demande :

J'initie un workspace :

et je peux initier un cluster Apache Spark en dernière version :




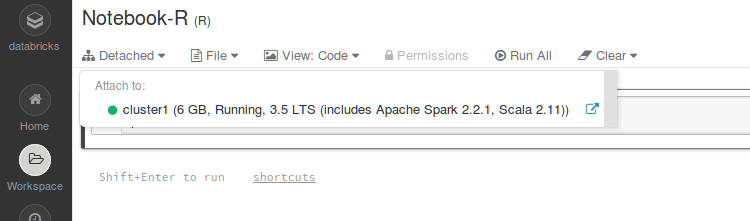
avec le Notebook ici en R associé :

ou en Scala (l'autre langage de la JVM le plus présent en datascience) avec ici l'exemple d'une connexion possible à Azure Cosmos DB:

Il fallait que je termine par Hortonworks qui a matérialisé son alliance avec Azure au sein de la distribution spécifique HDInsight (Hortonworks Data Platform 2.6 étant accessible en dernière version par l'intermédiaire de ce produit):


Je pars d'un cluster embarquant un serveur R avec RStudio Server et Hortonworks Data Platform :


J'obtiens pour le déploiement un cluster à 10 noeuds pour un coût d'environ 4.23 euros par heure :


et les métriques du cluster sont accessibles au travers du dashboard fourni par Apache Ambari :





avec l'état des services et les éventuelles alertes du cluster :

ou des disques des neouds du cluster :

Un notebook Jupyter avec iPython est disponible :


mais aussi le portail propre au cluster Hadoop :
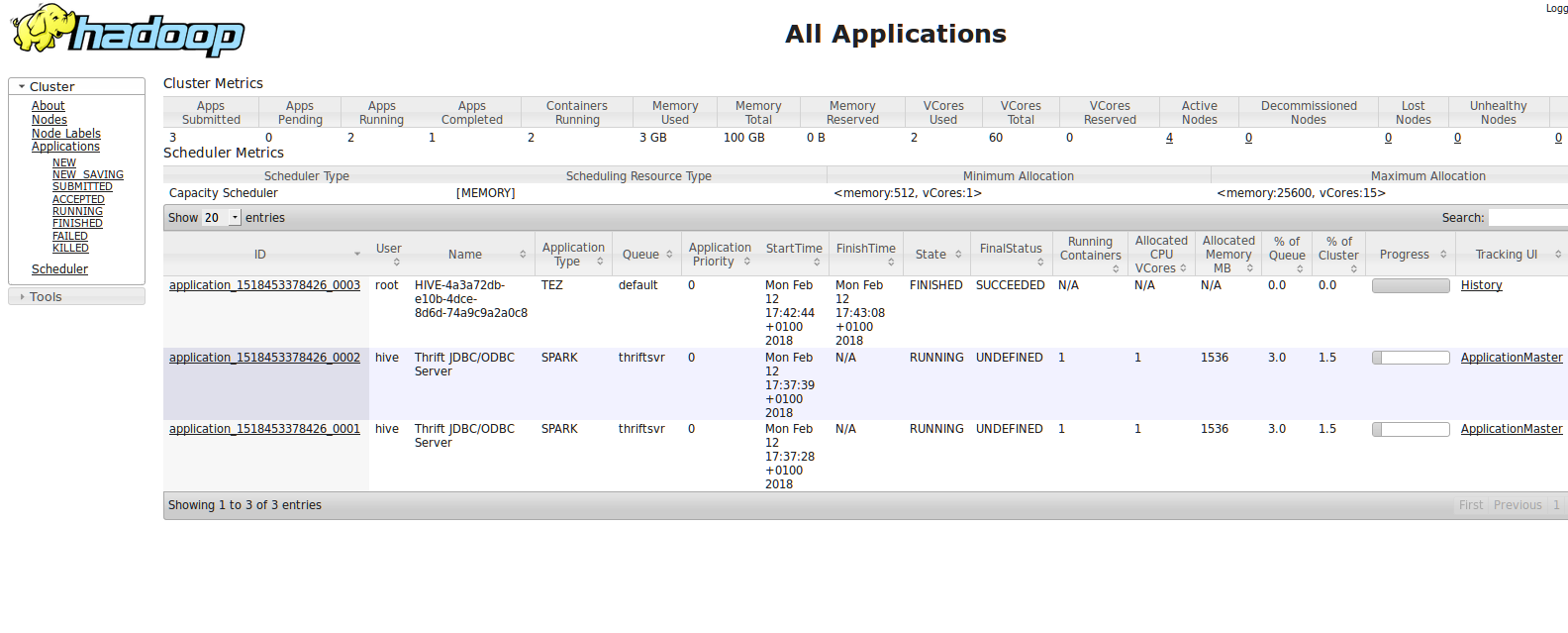
Il est possible de scaler le cluster avec des noeuds supplémentaires via le portail Azure :

Je teste le serveur RStudio connecté au cluster HDInsight :

et notamment la connectivité au cluster Hadoop via le package RHadoop :


je liste les fichiers embarqué dans le système de fichiers distribuées HDFS ou vers le stockage objet (Azure Blob Storage) :

ou avec un jeu de données test pré-fourni sur des horaires de vols :
et en appliquant un modèle de regression logistique (cher à Sayah) pour de la prédiction ...


ou un test de tâches parallèles avec les noeuds du cluster :

ou à Spark avec le package SparkR :




Je termine par la jonction entre le champ du Big Data avec le Machine Learning et en particulier le Deep Learning qui est en train de ce démocratiser (y compris sur nos smartphone avec l'apparition de Tensorflow Lite) via de nouvelles distributions comme par exemple H2O Driverless AI (la rencontre entre l'intelligence artificielle et les clusters Big Data) :


Pour cette expérience (qui ne dure "vraiment" "vraiment" "vraiment" pas longtemps) j'ai besoin de VMs très puissantes disposant de cartes GPU NVIDIA et très très chères (notamment avec les fameuses cartes GPU NVIDIA Tesla P100 que l'on ne verra peut être jamais dans le secteur public pour accélerer les traitements en Deep Learning) :




Je lance la création d'une seule VM (ça coûte vraiment cher) avec mon resource group dans Azure :


et je lance mes containers Docker liés à la carte GPU NVIDIA avec NVIDIA-Docker selon ce modèle :


lancement de ceux-çi avec mis à disposition du notebook H2O et de l'interface propre à H2O Driverless AI :

Il faut utiliser un jeu de données test à charger dans la VM :

L'intéret de la plateforme H2O Driverless AI est qu'elle analyse et classifie automatiquement son jeu de données sans avoir à appliquer une série d'algorithmes propres au Machine Learning (l'entrainement sur ce jeu de données et la génération de modèles est automatisé ici) :

On passe de la classification :

à la prédiction par exemple :
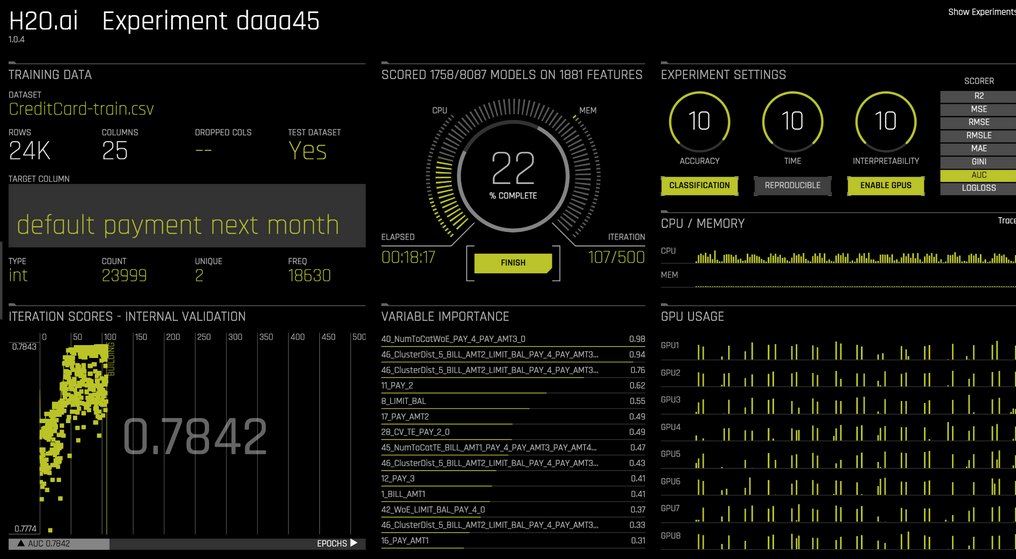
Un produit de la société H2O à succès puisqu'il permet d'être présent dans le TOP 5% des compétitions de datascience dans le monde via la plateforme communautaire Kaggle :

Le produit n'est pas terminé avec cette roadmap pour 2018 :

Après avec la montée en puissance de ces bases de données distribuées polymorphes rattachées aux grands Cloud Providers et généralement liées à leurs backends de stockage objets ultra performants (, on peut se demander si les cluster avec Hadoop sont encore l'avenir ...

Des évolutions à suivre ! ...


