.......
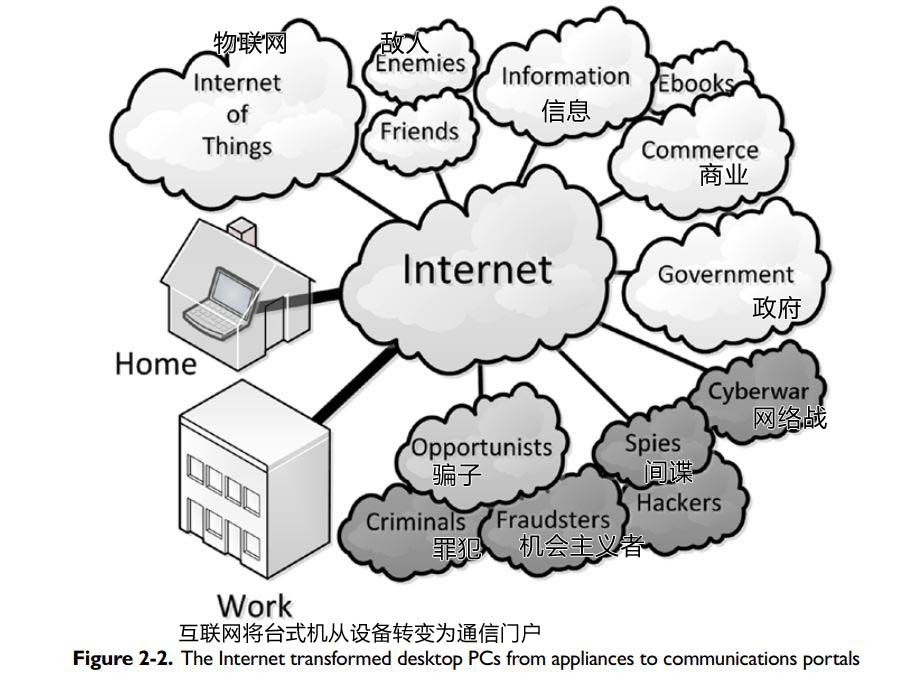
=v=The Internet The Internet was the next stage in the transformation of the personal computer from a stand-alone appliance like a typewriter or a stapler into a communications portal. Home computers were transformed in the same way, connecting home and office to a growing world of information, institutions, and activities. See Figure 2-2.
Network
The Internet is a network that connects other networks. When a business’ network connects to the Internet, all the computers that connect to the business’ network join the Internet. The computers connected in a network are called nodes. Nodes shows up often in computer science terminology. The Latin meaning of node is knot, a meaning that the word retains. In networking jargon, a node is a junction, a knot, where communication lines meet. Most of the time, a network node is a computer, although other network gear, such as switches and routers, are also nodes. When connected to the Internet, nodes are knitted together into a single interconnected fabric. Some nodes are connected to each other directly, others are connected in a series of hops from node to node, but, when everything is working right, all nodes connected to the Internet are connected and can communicate. At present, there are over three billion nodes connected into the Internet. The exact number changes continuously as nodes connect and disconnect.
The Internet led software designers and developers to think about computer applications differently. Instead of standalone programs like word processors and spreadsheets, they could design systems that provided complex central services to remote users. Timesharing mainframes and minicomputers had hosted applications that offered services to users on terminals, but the Internet offered a network, which is more flexible. In a network, nodes connect to any number of other nodes. A terminal in a typical time-sharing architecture communicates with a single host. In this architecture, terminals usually were not sophisticated and relied on the host for all computing. Communication between terminals must be routed through the central host. This kind of architecture is hard to expand. At some point, the number of terminals exceeds the load the host can support and the system has reached its limit. Sometimes the capacity of the central host can be increased, but that reaches a limit also. See Figure 2-3.
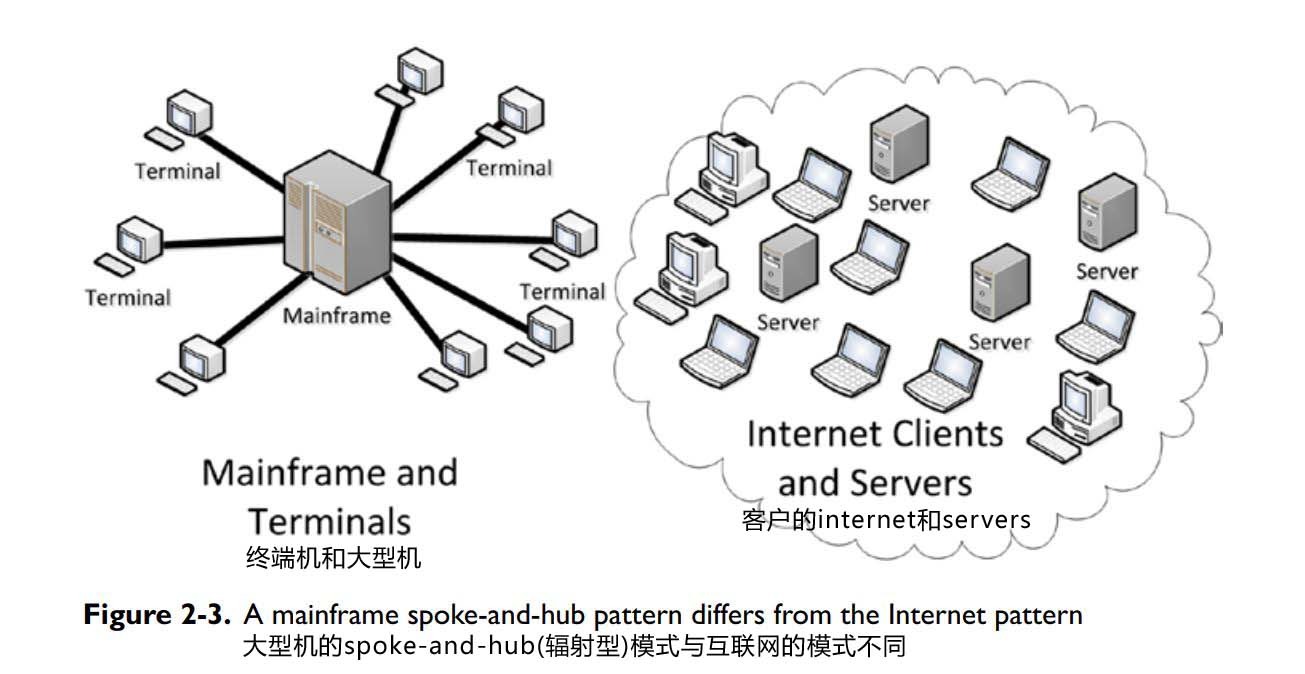
Within a network like the Internet, a system can expand by adding new servers, nodes that act like a mainframe host to provide information and processing to other client nodes, in place of a single host mainframe. With the proper software, servers can be duplicated as needed to support rising numbers of clients. On the Internet, users do not connect directly to a single large computer. Instead, users connect to the Internet, and through the Internet, they can connect to other nodes on the Internet. This connectivity implies that servers can be located anywhere within the reach of the Internet.
As the Internet blossomed, developers still tended to assume that no one was malicious. In the early 1990s, I was part of a startup that was developing a distributed application. Our office was in Seattle and our first customer was a bank located in one of the World Trade Towers in Manhattan. One morning, one of the developers noticed that some odd data was appearing mysteriously in his instance of the application. After a minute, he realized where it was coming from. Our first customer was unknowingly broadcasting data to our office. Fortunately, only test data was sent, but it could have been critical private data. If our customer had gone into production with that version of the product, our little company would have ended abruptly. The defect was quickly corrected, but it was only caught by chance. The development team missed a vital part of configuring the system for communication and did not think to monitor activity on the Internet. Until that moment, we did no testing that would have detected the mess.
Of course, our team began to give Internet connections more attention, but it would be a decade before Internet security issues routinely got the attention among developers that they do now. Mistakes like this were easy to make and they were made often, although perhaps not as egregious as ours.
Communication Portal
The decentralized connectivity of the Internet is the basis for today’s computers becoming communication portals that connect everyone and everything. Utilities like email are possible in centralized terminal-host environments, and attaching every household to a central time-sharing system is possible and was certainly contemplated by some pre-Internet visionaries, but it never caught on. Instead, the decentralized Internet has become the ubiquitous communications solution.
Much of the expansion of home computing starting in the mid-1990s can be traced to the growth of the home computer as a communications portal. A computer communications portal has more use in the home than a standalone computer. Before the Internet, most people used their home computer for office work or computer games. Not everyone has enough office work at home to justify an expensive computer, nor is everyone taken with computer games enough to invest in a computer to play them. The communications, data access, and opportunities for interaction offered by the Internet alter this equation considerably. 10: (Of course, it did not hurt that the price of computers began to plummet at the same time.)
The expansion of communication opportunities has had many good effects. Publishing on the Internet has become easy and cheap. Global publication is no longer limited to organizations like book publishers, news agencies, newspapers, magazines, and television networks. Email is cheaper and faster than paper mail and has less environmental impact. Electronic online commerce has thrived on the ease of communication on the Internet.
The Internet has reduced the obstacles to information flow over national boundaries. The browser has become a window on the world. New opportunities have appeared for both national and international commerce. Social media has changed the way families and friends are tie together. The transformation did not happen overnight, but it occurred faster than expected and is still going on.
The computer as a communications portal appeals to many more people than office functions and games. Everyone can use email and almost everyone is receptive to the benefits of social media. When the uses of computers were limited to functionality that required technical training, computer owners were a limited subgroup of the population with some level of technical insight. The group of those interested in social media and email has expanded to include both the most technically sophisticated and the most naïve. The technically naïve members of this group are unlikely to understand much of what goes on behind the scenes on their computer and its network. This leaves them more vulnerable to cybercrime.
Origins
The Internet did not spring from a void. It began with research in the 1960s into methods of computer communication and evolved from there to the Internet we know today. Often, the Internet is said to have begun with the development of the Advanced Research Projects Agency Network (ARPANET):(ARPANET is sometimes called the Defense Advanced Research Projects Agency Network (DARPANET). ARPA was renamed DARPA in 1972.), but without the network technology developed earlier, ARPANET would have been impossible.
ARPANET and the Internet
In the 1950s, mainframes in their glasshouse data centers were nearly impregnable, but a different wind had begun to blow. In the late 1950s, Joseph Lickliter (1915-1990), head of the ARPA, began thinking about connecting research mainframes as part of the research ARPA performed for the defense department. Lickliter wanted connect computers to provide access to researchers who were not geographically close to a research data center. He called his projected network the “Intergalactic Computer Network” in a memo to the agency.12( Accessed January 2016.)
Lickliter brought together researchers from the entire country. This group eventually developed the ARPANET. The network was designed to connect research computers, not, as is sometimes reported, as a command and control system that could withstand nuclear attack. Lickliter went on to other projects before the network was realized, but he is often called the originator.
The first incarnation of the ARPANET was formed on the west coast between Stanford, University of California Los Angeles, University of California Santa Barbara, and the University of Utah. These were university research centers, not top secret military centers, nor were they commercial data centers, processing inventories and accounts.
The concept of tying together isolated computers and knowledge was compelling. The objective was to include as many research centers as possible, not raise barriers to joining. At the height of the Cold War, fear of espionage was rampant, but apparently, no one thought about ARPANET as a means for spying on the research center network and little was done to secure it, beyond the usual precautions of keeping the equipment behind lock and key. The early ARPANET did not include commercial datacenters. Therefore, there may have been some concern about data theft, but money and finances were not on anyone’s mind.
During the 1980s and the early 1990s, two networking approaches contended. The ARPANET represented one approach. The other was IBM’s Systems Network Architecture (SNA). The two differed widely, reflecting their different origins.
Businesses needed to connect their computers for numerous reasons. Branches need to connect to headquarters, vendors to customers, and so on. To serve these needs, IBM developed a proprietary network architecture unrelated to the ARPANET. The architecture was designed for the IBM mainframes and minicomputers used by its business customers. It was implemented with communications equipment that IBM designed and built specifically for SNA. Non-IBM hardware could connect with SNA to IBM’s equipment, but SNA was not used to connect non-IBM equipment to other non-IBM equipment. In other words, SNA was only useful in environments where IBM equipment was dominant.
Almost all networks today are based on what is called a layered architecture. Instead of looking at network transmission as a single process that puts data on and takes data off a transmission medium, a layered architecture looks at the process as a combination of standardized parts that are called layers.
When put together for communication, the layers are called a network stack. For example, the bottom layer, called the physical layer, is concerned with signals on the transmission medium. This layer knows how to translate a message into the physical manifestations the transmission media must have. If the medium is copper wire, the layer is a software and hardware module designed and built to put modulated electrical signals on copper wire at the proper voltage and frequency. If copper wire is replaced by optical fiber, the copper wire module is replaced by an optical fiber module that reads and writes light pulses. When a layer in the stack is replaced, the other layers do not have to change because each layer is designed to interact with the other layers in a standard way.
Layers work like an electric plugs and sockets. It doesn’t matter whether you plug a lamp or an electric can opener into a wall socket. Both will work fine. Also, the electricity could come from a hydro-electric dam, a windmill, or a gas generator out back. The lamp will still light and you can still open the can of beans because the socket and the electricity is the same. You replace a layer in a network stack in the same way. If what goes in or comes out meets its specification, what happens in between does not matter. You can think of each network layer as having a plug and socket. An upper layer plugs into the socket on the next lower layer. If each pair of plugs and sockets meet the same specification, the stack works.
A layered network architecture is a tremendous advantage, as is the standard design of electricity sources and electrical appliances. When the need arises, you can switch sources. If you lose power during a storm, you can fire up your private gas generator and the lamp still lights. This also applies to networking. If copper is too slow, you can replace it with optical fiber and replace the copper bottom layer module with a fiber module. This saves much time and expense because the entire network stack does not need to be rewritten. When connecting to another network, only the top layers where the connection occurs need be compatible. Typically, networks are divided into seven layers. The bottom layer is the only layer that deals with hardware. The rest are all software.
In addition to being an early adopter of a layered network architecture, ARPANET used packet switching for message transmission. Packet switching divides a message into chunks called packets. Each of these packets is addressed to the destination network node. Each packet finds its own way through the network from one switching node to the next. A switching node is a special computer that can direct a packet to the next step toward the target address. Since there is usually more than one way to travel from source to destination, the network is resilient; if one path is blocked, the packet is switched to another path and the packet eventually gets through. When all the packets arrive at the destination, they are reassembled and passed to the receiving program.
A group researching a military communications network that could survive a catastrophe, such as a nuclear attack, discussed the concept of a packet switching network. The ARPANET was not developed by this group, but the ARPANET team put packet switching to work in their network and gained the resiliency that military communications required.
There are other advantages to packet switching beyond resilience. It is very easy to connect to an ARPANET-style network. Part of this is due to the layered architecture. For example, if a network based on a different transmission technology wants to join the Internet, they develop a replacement layer that will communicate with the corresponding layer in the ARPANET network stack and they are ready to go without re-engineering their entire implementation. When a new node joins the Internet, other nodes do not need to know anything about the newcomer except that its top layer is compatible. The newcomer only needs to be assigned an address. The switching nodes use the structure of the address to begin to direct packets to the newcomer.
The layered architecture facilitates ease in entry by not mixing lower level concerns and application code. Application changes do not require changes deep in the stack that would prevent connections with nodes without the lower level changes. This explains the rich array of applications that communicate over the Internet with nodes that are unaware of the internals of the application.
ARPANET also developed basic protocols and addressing schemes that are still in use today. These protocols are flexible and relatively easy to implement. A layered architecture and packet switching contribute to the flexibility and ease. The basic Internet protocol, Transmission Control Protocol over Internet Protocol (TCP/IP) conducts messages from an application running on one node to another application running on a node, but it is the job of the node, not the network, to determine which application will receive the message.
The flexibility and ease of connection profoundly affected IBM’s SNA. By the mid-1990s, SNA was in decline, rapidly being replaced by the Internet architecture. SNA was hard to configure, required expensive specialized equipment, and was hard to connect to non-SNA systems. By the mid-1990s, SNA systems were often connected over Internet-type networks using tunneling: hiding SNA data in Internet messages, then stripping away the Internet wrapper for the SNA hardware at the receiving end. This added an extra layer of processing to SNA communication.
The SNA connection from computer to computer is relatively inflexible. There was no notion of sending or receiving a message to or from another computer that any application able to handle the message could respond to the message. This is one of the features that makes Internet-style communication flexible and powerful, but it also eases intrusion into application interaction, which is the basis of many cybercrimes. It is not surprising that financial institutions were late to replace SNA with the ARPANET-style networking of the Internet.13:(For a detailed technical description of SNA in a heterogeneous environment, see R. J. Cypser, Communications for Cooperating Systems: Osi, Sna, and Tcp/Ip, Addison-Wesley, 1991.)
An ARPANET-style layered network architecture separates the authentication of the source and target of a message from the transmission of the message. Generally, this is advantageous because combining transmission and authentication could degrade the performance of transmission as identities and credentials are exchanged. Proving who you are requires complex semantics and negotiations. Quickly and efficiently moving raw bits and bytes from computer to computer does not depend on the semantics of the data transferred. Including semantics based authentication slows down and complicates the movement of data.
The ARPANET architecture choice was practical and sound engineering, but it was at the expense of the superior security of SNA. 14:(Not everyone agrees on the security of SNA. See Anura Gurugé, Software Diversified Services, “SNA Mainframe Security,” June 2009) In SNA, unlike ARPANET, transmission and authentication were combined in the same layer. This meant that adding a new node to a network involved not only connection but authentication, proving who and what the new node was. This made adding new nodes a significant configuration effort, but it also meant that the kind of whack-a-mole contests that the authorities have today with hacker sites would be heavily tilted in the authorities’ favor.
Taken all together, a layered architecture, packet switching, and a remarkable set of protocols add up to a flexible and powerful system. These characteristics were chosen to meet the requirements that the ARPANET was based upon. The ARPANET was transformed into today’s Internet as more and more networks and individuals connected in.
World Wide Web
The World Wide Web (WWW), usually just “the Web,” is the second part of today’s computing environment. Technically, the Web and the Internet are not the same. The Web is a large system of connected applications that use the Internet to communicate. The Web was developed to share documents on the Internet. Instead of a special application written to share each document in a specific way, the Web generalizes document format and transmission. From the end user’s standpoint, the visible part of the Web is the browser, like Internet Explorer, Edge, Firefox, Chrome, and Safari.
A browser displays text received in a format called Hypertext Markup Language (HTML). Computers that send these documents to other nodes have software that communicates using a simple scheme that creates, requests, updates, and deletes documents. The browser requests a document and the server returns with a document marked up with HTML. The browser uses the HTML to decide how to display the document. The richness of browser displays is all described and displayed following HTML instructions. Although this scheme is simple, it has proved to be exceptionally effective.
And it goes far beyond simple display of documents. The first web servers did little more than display a directory of documents and return a marked up copy to display in an HTML interpreter. Browsers put the request, update, and display into a single appliance. Browsers also implement the hyperlinks that make reading on the Internet both fascinating and distracting. A hyperlink is the address of another document embedded in the displayed document. When the user clicks on a link, the browser replaces the document being read with the document in the hyperlink. Everyone who surfs the Net knows the seductive, perhaps addictive, power of the hyperlink.
As time passed, servers were enhanced to execute code in response to activity on browsers. All web store fronts use this capability. When the user pushes an order button, a document is sent to the server that causes the server to update an order in the site’s database and starts a process that eventually places a package on your front porch.
The documents and markup languages passing between the client and server have become more elaborate and powerful as the web evolved, but the document-passing protocol, Hypertext Transfer Protocol (HTTP), has remained fundamentally unchanged. In fact, the use of the protocol has increased, and often has nothing to do with hypertext.
Most applications coded in the 21st century rely on HTTP for communication between nodes on the network. Servers have expanded to perform more tasks. Many uses of the protocol do not involve browsers. Instead, documents are composed by programs and sent to their target without ever being seen by human eyes. The messages are intended for machine reading, not human reading. They are written in formal languages with alphabet soup names such as XML and JSON. Most developers are able to read these messages, but no one regularly looks at messages unless something is wrong. Typically, the messages are delivered so fast and in such volumes that reading all the traffic is not feasible. The average user would find them incomprehensible.
The Web has evolved to become the most common way of sharing information between computers, both for human consumption and direct machine consumption. Even email, which is often pure text, is usually transferred over the Web.
The ubiquity of data transfer over the Web is responsible for much of the flourishing Internet culture we have today. Compared to other means of Internet communication, using the Web is simple, both for developers and users. Without the Web, the applications we use all the time would require expensive and tricky custom code; they would very likely have differing user interfaces that would frustrate users. For example, a developer can get the current temperature for many locations from the National Weather Service with a few lines of boilerplate code because the weather service has provided a simple web service. Without the Web, the attractive and powerful applications that communicate and serve us would not be here.
Opportunities for development are also opportunities for crime. Developers are challenged with a learning curve when they work on non-standard applications. They are much more effective when they work with standard components and techniques. The Web provides a level of uniformity of components and techniques that make development more rapid and reliable.
However, these qualities also make criminal hacking more rapid and reliable. An application that is easier to build is also easier to hack. A hacker does not have to study the communications code of a web-based application because browsers and communications servers are all similar. The hacker can spot an application to hack into and immediately have a fundamental understanding of how the application works and its vulnerable points.
The Perfect Storm
As marvelous as personal computing devices, the Internet, and the World Wide Web are, they are part of a perfect storm that has propelled the flood of cybercrime that threatens us. The storm began to hit in the late 1990s.
The very success of the PC has engendered threats. PCs are everywhere. They sit on every desk in business. They are on kitchen tables, in bedrooms, and next to televisions in private homes. In the mid-1980s, less than 10% of US households had a PC. 15:(See “Top Ten Countries with Highest number of PCs,”) That rose by a factor of six to over 80% percent in 2013. 16:(Thom File and Camille Ryan, “Computer and Internet Use in the United States: 2013”, U.S. Census Bureau, November 2014)
Contrast this with the 1970s when the Internet was designed and began to be deployed among research centers. The Internet was for communication among colleagues, highly trained scientists, and engineers. In 2013, the training of most Internet users did not go beyond glancing at a manual that they did not take time to understand before throwing it into the recycling bin. In 1980, computer users were naïve in a different way; they expected other users to be researchers and engineers like themselves, but they were also sophisticated in their knowledge of their software and computer equipment, unlike the typical user of today. The 1980 user was also more likely to know personally the other users on the network with whom they dealt.
Users today are often dealing with applications they barely comprehend and interacting with people they have never seen and know nothing about. This is a recipe for victimization. They are using a highly complex and sophisticated device that they do not understand. Many users are more familiar with the engine of their car than the workings of their computer. Unlike the Internet designers, users today deal with strangers on the Internet. Strangers on the street reveal themselves by their demeanor and dress. Through computers, Internet strangers can be more dangerous than street thugs because they reveal only what they want to be seen and readily prey on the unsuspected.
Computer hardware and software designers have been slow to recognize the plight of their users, both businesses and individuals. Until networked PCs became common, PCs only needed to be protected from physical theft or intrusion. The most PCs needed was a password to prevent someone from the next cubicle from illicit borrowing. Consequently, security was neglected. Even after PCs began to be networked, LANs were still safe. Often, security became the last thing on the development schedule, and, as development goes, even a generous allotment of time and resources for security shrank when the pressure was turned on to add a feature that might sell more product or impress the good folk in the C-suite. In an atmosphere where security was not acknowledged as a critical part of software and hardware, it was not developed. Even when it was thought through and implemented, experience with malicious hackers was still rare, causing designs to miss what would soon become real dangers.
The Soviet Union crashed in the 1990s, just as naïvely secured computers were beginning to be connected to the Internet, which was engineered to have a low bar of entry and designed with an assumption that everyone could be trusted. One of the consequences of the fall of the Soviet Union was that many trained engineers and scientists in Eastern Europe lost their means of livelihood. In some locations, government structures decayed and lawlessness prevailed. The combination of lawlessness and idle engineers who were prepared to learn about computing and connecting to the Internet was fertile ground for the growth of malicious and criminal hackers looking for prey.
The Internet is borderless. Unless a government takes extraordinary measures to isolate their territory, a computer can be anywhere as soon as it connects. If a user takes precautions, their physical location can be extremely hard to detect. A malicious hacker located in an area where the legal system has little interest in preventing hacking is close to untouchable.
The Web and its protocols are brilliant engineering. So much of what we enjoy today, from Facebook to efficiently managed wind-generated power, can be attributed to the power of the Web. The ease with which the Web’s infrastructure can be expanded and applications designed, coded, and deployed has the markings of a miracle. However, there is a vicious downside in the ease with which hackers can understand and penetrate this ubiquitous technology.
The perfect storm has generated a loosely organized criminal class that exchanges illegally obtained or just plain illegal goods in surprising volumes, using the very facilities of the Internet that they maraud. And these criminal bazaars increase the profit from crime and the profits encourage more to join in the carnage.
A solution is under construction. The computing industry has dropped its outmoded notion that security is a secondary priority. More is being invested in preventing cybercrime every year. Crime does not go away quickly; perhaps it never disappears, but with effort, there are ways to decrease it. One of the ways is to be aware and take reasonable precautions. The next chapter will discuss some of the technological developments that help.